

実践で学ぶ コーパス活用術 |
|
16 青木 理香 コーパスで話し言葉を探る ―― 基礎編―― |
© (WT-shared) Matthew 6476 |
この連載では、これまで様々な種類のコーパスを扱ってきましたが、その多くは書き言葉を主としたものでした。しかし、現在実際に話されている「生の英語」を知るためには、書き言葉だけではなく、話し言葉についても注意を払う必要があります。今回から2回にわたり、話し言葉コーパスを扱います。その中でも、特に音声コーパスに焦点を当てて説明していきたいと思います。
| 1 | 話し言葉コーパスとは |
コーパスを作る際に最も重要となる作業に、データの収集があります。みなさんは、書き言葉のデータを集めるとしたら、どのような方法をとるでしょうか。書物、新聞、雑誌、広告、パンフレット、作文など、多くの媒体から、様々な状況下で書かれたデータを得ることができると思います。さらに現代では、ブログ、掲示板、SNS などのウェブ上の媒体にも書き言葉があふれているため、データを集めることよりも、取捨選択することに苦労するかもしれません。
では、話し言葉のデータを集めるにはどうしたらよいでしょうか。テレビ番組、映画、ラジオ、講演会や講義の録音、電話の録音などが思い浮かぶでしょう。協力者を募って、会話を録音させてもらうという方法もあります。しかし、これらの方法を使って、個人で大量のデータを集めることは容易ではありません。様々なコミュニティーから協力者を探し、録音やインタビューの許可を取るには、多くの時間を要します。さらに、話し言葉のコーパスを作る場合は、発話された談話を書き起こす必要があります。ただ文字に起こすだけならよいのですが、場合によってはイントネーション・言いよどみ・ポーズ・ジェスチャー・談話構造など、多岐にわたる要素をデータ化する必要があります。こうした作業には、多くの時間と人員が必要になります。
このような理由で、話し言葉コーパスの発展は、書き言葉コーパスに比べて遅れています。書き言葉コーパスには収録語が1億語を超えるものがたくさんありますが、話し言葉コーパスにはほとんどありません。しかし、近年のテクノロジーの進歩によって、以前よりも録音・データ保存・書き起こし・分析が容易になったことで、話し言葉コーパスの種類やデータ量も増えてきました。
話し言葉コーパスの利点は、冒頭でも述べたように、自然に発話されている談話のデータを手に入れられることです。話し言葉ではどのような語や文法が使われているのか、といった言語学的研究が容易にできるようになりました。さらに、書き言葉コーパスのデータと比較すれば、話し言葉に特有の言語的特徴を捉えることもできます。
また、話し言葉コーパスに含まれる音声データを使うと、談話全体だけでなく個々の音素[1] や音節[2] を抽出することもできるため、自然発話における個々の音素の発音やイントネーションなどについて、音響的分析をすることも可能になりました。話者やシチュエーションに関する情報を有するコーパスならば、方言・年齢・ジャンルなどが、発話にどのような影響を与えるのかを調べることができます。
例えば、年齢・コミュニティーによる発音の違いを扱った研究として、Linguistic innovators: The English adolescents in London という、ロンドン英語の調査プロジェクトのために作られたコーパス(16〜19歳の若者100人による140万語の話し言葉を収録)を使ったものがあります。[3] ロンドンのハクニーとヘーブリングのイングランド系[4]・非イングランド系[5] の若者による話し言葉の発音と、新たに録音された70〜80代のイングランド系高齢者の話し言葉における発音を分析し、年齢とコミュニティーが発音の変化にもたらす影響を調べることを目的とした研究です。ロンドン英語の子音の主な特徴として、1) 語頭の /h/ が脱落する(例: hate と eight が同じ発音になる)、2) 歯摩擦音 /θ/, /ð/ を /f/, /v/ や /t/, /d/ の音で発音する(例: three と free, they と day が同じ発音になる)、3) 強勢を持たない /t/ が声門破裂音 /ʔ/ になる(例: butter が [bʌʔə] と発音される)、などが挙げられますが、この研究の結果、次のようなことが明らかになりました。
■ 若者が話すロンドン英語では、語頭の /h/ が脱落する割合が、高齢者と比べて有意に低い(若者11%; 高齢者58%)
■ 若者が話すロンドン英語では、/θ / の音素を [f] の音を使って発音する傾向が強くなっている(若者86.5%; 高齢者29.7%)
■ 語頭の /h/ を脱落させる割合は、若者の中でも、イングランド系に比べて非イングランド系のほうが低い(イングランド系18%; 非イングランド系3.9%)
■ /ð/ の音素を [d] の音で発音する傾向は、非イングランド系の若者のほうが強い(イングランド系42%; 非イングランド系67.2%)
このように、話し言葉コーパスは様々な分野の研究に使われています。
| 2 | 話し言葉コーパスの種類 |
| (1) | 話し言葉コーパスの目的 |
話し言葉コーパスは、主に (a) 音響分析、(b) 談話分析のために構築されます。コーパスを作る目的によって、どのような情報が収録されるかが変わってきます。
(a) 音響分析のために作られたコーパス:
一般的に、高音質の音声ファイル、音素・音節・語の区切りに関する情報、イントネーション・ピッチの情報などが収録されており、詳細な音声学的情報を得ることができる。
(b) 談話分析のために作られたコーパス:
収録されている音声ファイルには雑音が多く、低音質である代わりに、収録時間が長いという特徴がある。また、談話が起こっているコンテクストや話者に関する情報、ジェスチャーに関する情報などが含まれていることもある。
近年では、話者のジェスチャーや目線、表情などの非言語的行動の分析のために、談話の様子を収録した映像を含むコーパスも出てきました。ただし、話者のプライバシー保護のため、個人情報に関する語が削除されていたり、ピッチ(声の高さ)が加工されていたりすることが多いです。
| (2) | 話し言葉コーパスと音声コーパス |
話し言葉コーパスは、英語で Spoken Corpus と呼ばれます。話し言葉コーパスには、談話を書き起こしたテキストのみを含むものと、実際の音声ファイルや音声学的情報を含むものがあり、後者のコーパスを特に Speech Corpus(音声コーパス)と呼んで前者と区別することがあります。例えば、この連載の第2, 3回で扱われた British National Corpus(BNC)は、話し言葉のデータも含んでいますが、全体の10%ほどしか占めない上、音声ファイルの音質が悪く、音声コーパスとは言えません。それに対して、(1) の (a) で述べたような音響分析のために構築されたコーパスは、すべて音声コーパスに分類することができます。
| 3 | 音声コーパス |
さて、ここからは、音声コーパスについて見ていきましょう。
音声コーパスが扱うデータには、主に、読み上げ音声(ニュースの原稿・文章の朗読・単語リストなど)と自然発話(複数人による談話・1人で行う談話)の2種類があります。
読み上げ音声と自然発話の両方のデータを収録しているコーパスの例として、イギリス・アイルランドの9都市に住む16歳の若者による英語を収録した IViE(Intonational Variation in English Corpus)があります。IViE は、文の読み上げ・節の読み上げ・地図を使った案内タスク・聞いた物語を自分の言葉で言い直すタスク・自由対話における音声を提供しています。
音声コーパスに収録されている音声ファイルは、どのようなものなのでしょうか。以下の URL に IViE の音声データの一部が公開されていますので、この URL にアクセスして、興味のある方言・性別・スタイルを選び、音声を聞いてみましょう。
http://www.phon.ox.ac.uk/files/apps/IViE/search.php
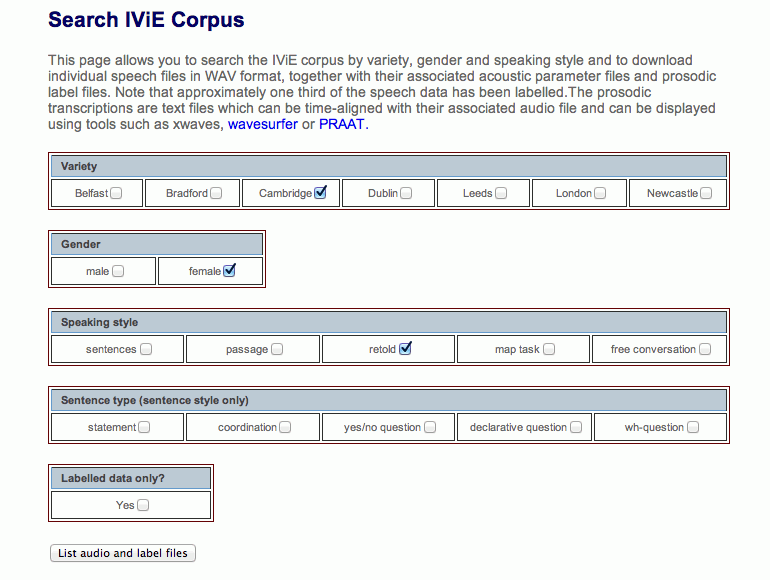
聞きたい音声の種類のボックスにチェックを入れ、一番下の List audio and label files というボタンを押すと、以下のように音声のリストが出てきます。

各表の Audio file の位置にあるリンクをクリックしてください。wav ファイルが開き、音声を聞くことができます。文と節のスクリプトは、以下のページで見ることができます。
http://www.phon.ox.ac.uk/files/apps/IViE/stimuli.php
このコーパスによって、方言やスタイルについて比較研究することができます。実際、IViE を使った研究により、方言とスタイルがイントネーションに与える影響が明らかになっています。例えば、“We live in Ealing.”, “You are feeling mellow.” などの平叙文においては、標準的な発音では、文末に下降調のイントネーションが現れますが、ニューカッスルやベルファストの方言では、文末に疑問文のような上昇調のイントネーションが多く現れることがわかりました。[6] 実際、ケンブリッジ地方では、下降調のイントネーションは、平叙文全体の97%以上を占めましたが、ニューカッスルでは83%、ベルファストでは9%に下がっています。また、同一話者の様々なスタイルにおける発音の特徴を調べた研究では、聞いた物語を自分で言い直すタスクにおいて、他のタスクよりも上昇調が多く見られ、下降調の出現が少ない、ということがわかりました。[7]
ウェブページの冒頭に書いてあるように、このコーパスは、現在全体の約3分の1のデータについてのみ音声情報が付与されています。自由発話のスクリプトを手に入れたい場合や、詳しく発音を分析したい場合は、選択画面の一番下の項目 Labelled data only? にチェックを入れてください。なお、発音分析の進め方は、次回の実践編で扱います。
IViE のように、英語母語話者の音声を収録した音声コーパスのうち、利用しやすいものを表1にまとめました。無償で公開されているものも多いので、興味があるものにアクセスしてみてください。
| コーパス名 | 対象 | データ量 | 主な用途 | URL |
|---|---|---|---|---|
| MARSEC (The Machine Readable Spoken English Corpus) |
1980年代のイギリス英語、ラジオ放送の録音 | 5.5万語 | 音響分析、音声言語処理 | http://www.reading.ac.uk/AcaDepts/ll/speechlab/marsec/ |
| SWB (The Switchboard Corpus in NXT) |
1990年代初頭のアメリカ英語、電話会話の録音 | 300万語 | 談話分析、音声言語処理 | http://groups.inf.ed.ac.uk/switchboard/ |
| SBCSAE (Santa Barbara Corpus of Spoken American English) |
アメリカ英語、様々なシチュエーションにおける自由発話 | 24.9万語 | 談話分析 | http://www.linguistics.ucsb.edu/research/santa-barbara-corpus/ |
| EUSTACE (Edinburgh University Speech Timing Archive and Corpus of English) |
イギリス英語、文リストの読み上げ音声 | 4,600文 | 音響分析 | http://www.cstr.ed.ac.uk/projects/eustace/ |
| HCRC Map Task Corpus | イギリス英語、地図を使った案内タスクにおける発話 | 15万語 | 音響分析、音声言語処理、談話分析 | http://groups.inf.ed.ac.uk/maptask/ |
| Buckeye Corpus | アメリカ英語、インタビューにおける発話 | 30万語 | 音響分析、音声言語処理、談話分析 | http://buckeyecorpus.osu.edu |
| 4 | 日本人英語学習者音声コーパス |
音声コーパスの中でも、第二言語学習者の音声コーパスの数は少なく、その中でも日本人英語学習者を対象とするものはわずかです。この連載の第9, 10回では日本人英語学習者のデータが収録されたコーパスを扱いましたが、紹介された5つのコーパスの中で、音声ファイルを含んでいるものはありません。
2014年の5月に、ICNALE-Spoken と呼ばれる、アジア圏英語学習者の発話データ(音声ファイルとスクリプト)を収録したコーパスの小型版が公開されました。これは、第9, 10回で紹介された ICNALE の延長として構築されているもので、現在は日本人学習者を含むアジア4カ国の英語学習者よる自由発話音声(与えられたトピックについて話す)のデータが15万語分収録されています。以下のページの手順に従ってダウンロードすることができます。
http://language.sakura.ne.jp/icnale/download.html
ただし、録音は国際電話を使って収集されているため、音質が悪く、音響分析には向いていません。その代わりに、英語母語話者のデータも収録されていますので、母語話者と学習者の談話を比較し、学習者の自由発話における談話の特徴を分析することができます。今後、随時データが追加されるようです。
現在、手に入れることができる日本人英語学習者の音声コーパスの中で最も代表的なものは、UME-ERJ(English Speech Database Read by Japanese Students, 日本語では「日本人学生による読み上げ英語音声データベース」)です。以下の URL で、詳細を見ることができます。申請をすれば、無償でコーパスの DVD を手に入れることができます。
http://research.nii.ac.jp/src/UME-ERJ.html
このコーパスは、自動音声認識プログラムの開発などの音声言語情報処理技術の基盤となるデータベース作りを目的にしており、日本人大学生による様々な音素・強勢・イントネーション・リズムを含む語や文の読み上げ音声を収録しています。
語リストには、以下のようなミニマルペア[8] などが含まれています。単語の下の角括弧で囲われたアルファベットの記号は、語の発音を示しています。なお、学習者たちは、事前に発音を確認し、練習してから録音できることになっています。

文リストには、以下の2文のように、文の区切りの位置を意識させるもの、

下の2つの会話のように、情報の新旧によって使い分けられるイントネーション曲線を意識させたもの、
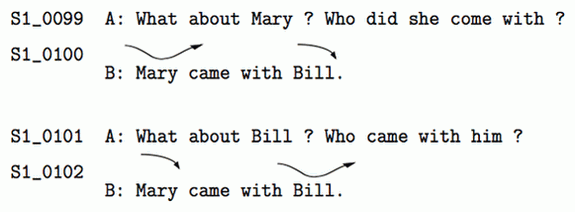
さらに、次の4文のように、強勢の位置や強弱を意識させたものが含まれています(以下の文リストでは、@が強い強勢、+が弱い強勢、−が弱勢を表しています)。

収録された音声は、学習者が強勢やイントネーションに関する解説を事前に読み、これらの文を納得がいくまで練習してから録音されたものです。
また、英語母語話者による読み上げ音声と、学習者の音素・強勢・リズム・イントネーションに関してアメリカ人英語教師が行った5段階の評価(正確性スコア)のデータも含まれています。これにより、学習者音声の音声学的な特徴と、英語母語話者による正確性の評価の関係を分析することができます。実際に、UME-ERJ のリズムがコントロールされた文を利用した研究を紹介します。

日本人英語学習者によって読み上げられた上の4文について、計測された音節長と、リズムに関する正確性スコアとの関係を調べたところ、弱勢を持つ母音(ここでは、−で記された音節の母音)の持続時間がより短い学習者のほうが、より高いスコアを得ることが明らかにされました。[9] つまり、弱母音の長さと、客観的な正確性評価には相関関係があり、弱母音を短く発音した学習者の発音は、そうでない学習者の発音に比べ、よりネイティブスピーカーに近いと評価されたということです。
| 5 | おわりに |
今回は、書き言葉コーパスと話し言葉コーパスの違い、話し言葉コーパスの種類、そして音声コーパスの種類について、例を交えながら概観しました。次回は、話し言葉コーパスや音声コーパスを、実際に英語教育や研究に役立てる方法について説明していきます。
|
〈著者紹介〉 青木 理香(あおき りか) 埼玉大学英語教育開発センター助教。専門は音声学、外国語教育。特に、日本人学習者による英語音声習得、バイリンガル・トリリンガルの音声習得などに関心がある。現在は、日中バイリンガルによる英語破裂音の知覚と産出を中心に研究を進めている。執筆に参加した辞書に Kernerman Japanese French Learners' Dictionary (K Dictionaries), 『プログレッシブ英和中辞典 第5版』(小学館)などがある。 |
〈注〉
[1] ある言語において、語の意味を区別する機能を持つ音の最小単位。例えば英語では、British という単語は、/britiʃ/ という6つの音素で成り立っていると考えられます。
[2] ある言語の話者が、ひとまとまりであると認識する音の単位。例えば英語では、London という単語は、Lon-don という2つの音節から成り立っていると認識されます。
[3] Cheshire, J., S. Fox, P. Kerswill, and E. Torgersen (2008) “Ethnicity, Friendship Network and Social Practices as the Motor of Dialect Change: Linguistic Innovation in London.” Sociolinguistica Jahrbuch, 22: 1-23.
[4] ロンドンにルーツを持つ、白人のロンドン英語話者。
[5] アジアやアフリカにルーツに持つ、移民の子孫のロンドン英語話者。
[6] Grabe, E., G. Kochanski, and J. Coleman (2005) “The Intonation of Native Accent Varieties in the British Isles: Potential for Miscommunication?” Katarzyna Dziubalska-Kołaczyk, and Joanna Przedlacka (eds.), English Pronunciation Models: A Changing Scene. Linguistic Insights Series 21. Peter Lang, 311-37.
[7] Grabe, E. (2006) “A Quantitative Model of Intonational Variation in the British Isles: ESRC End of Award Report, RES-000-23-0149.” Swindon: ESRC.
[8] 1つの音素のみの違いで区別される語のペア。例えば、beat /biːt/ と bit /bit/ という2語は、母音のみの違いで意味が異なる語になるので、ミニマルペアであると言えます。
[9] Nakamura, S. (2010) “Analysis of Relationship between Duration Characteristics and Subjective Evaluation of English Speech by Japanese Learners with regard to Contrast of the Stressed to the Unstressed.” Journal of Pan-Pacific Association of Applied Linguistics, 14(1): 1-14.
|
キーワードで書籍検索 コーパス corpus 話し言葉 音素 音節 談話分析 |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |