

実践で学ぶ コーパス活用術 |
石井 康毅 英語コーパス体験ツアー ――BNCweb を検索してみる―― (後編) |
|
前編では「like+to+動詞」と「like+動名詞」を題材として、BNCweb の基本的な使い方を紹介しました。今回の後編でも引き続き、「〜するのが好きだ」という意味で like の後に来る to 不定詞と動名詞の使い分けに何らかの傾向があるのかを調べるという試みを通して、BNCweb の応用的な機能を紹介しながら、コーパス検索がどういう分析を得意としているのかを見ていきます。
| 6 | コロケーション抽出機能 |
前編の最後では、「動詞の like(変化形を含む)+to+動詞」と「動詞の like(変化形を含む)+動名詞」の用例を見る方法を紹介しましたが、to 不定詞や動名詞としてどのような動詞がどのくらいの頻度で使われているのかを、もっと分かりやすく知りたいと思うかもしれません。BNCweb では、このような場合に、表の形式で表示してくれる方法が用意されています。それがコロケーション抽出機能です。コロケーション抽出機能は、検索した語句を中心とした前後の位置で使われている単語を集計して、一覧表示します[1]。
それでは、「動詞の like(変化形を含む)+to」の直後に来る動詞を調べてみましょう。(以下、「動詞の like(変化形を含む)」という書き方は、単に「like」と省略することにします。また、前編と同様に、実際に入力する文字が分かりやすいように、半角スペースで入力すべき部分を ␣ で示します。)手順は以下の通りです。
1 まずは、「like+to」に対応する {like}_{V}␣to を通常の方法で検索します。
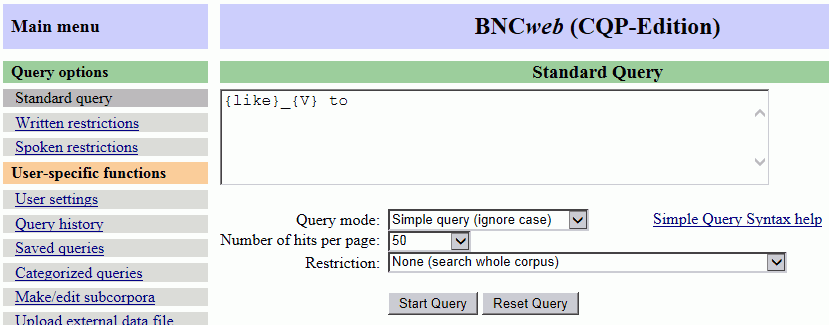
2 検索結果ページのドロップダウンリストで Collocations... を選択し、 ボタンをクリックします。

3 以下の3つの設定項目を指定する画面に切り替わります。
- Calculate over sentence boundaries:
文境界をまたいだ前後の単語、つまり指定の語数の範囲内であれば別の文中で使われている単語まで集計対象とするかどうかを選択します。(初期値は no) - Include lemma information:
前後の単語の原形が何であるかという情報を含めて集計するかどうかを選択します。(lemma は通常「見出し語」と訳されますが、辞書などで見出し語として扱われる語形、つまりいわゆる原形のことです。)yes にすると変化形を全て原形に戻して集計したコロケーションのリストも得られるようになります。(初期値は no) - Maximum window span:
前後何語を対象に集計するかを選択します。(初期値は5)
今回は [Include lemma information] を yes に変更し、 ボタンをクリックします。
4 「like+to」の前後5語の範囲内で使われている単語のリストが表示されます。この段階ではまだ原形に戻して集計したリストにはなっていません。順番は、コーパスデータからコロケーションを抽出する際によく使われる統計指標の1つである、Log-likelihood の値の降順でソートされています。
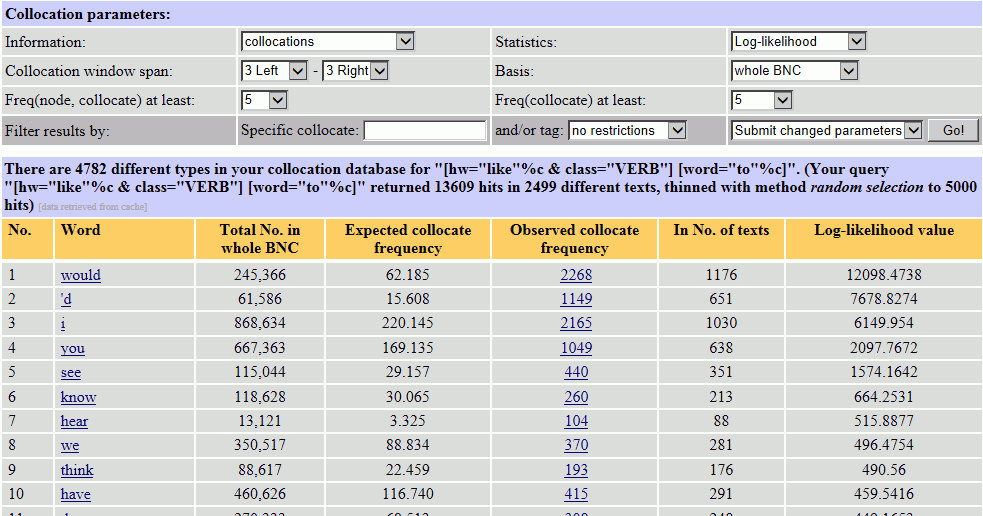
5 さらに品詞、位置、ソート方法などを指定することができます。例えば、[Information:] を collocations on lemma に、[Collocation window span:] を 1 Right - 1 Right に、[and/or tag:] を any verb に変更して ボタンをクリックします。

これで、「like+to」の1語右の位置で使われている動詞を原形に戻して集計したリストが手に入りました。(ただし、この手順で表示される頻度は、{like}_{V}␣to で検索した時点で検索結果が13,609件あったため、その中から無作為抽出された5,000件のデータに基づくものです。)「like+to」に続く動詞としては、see, know, think, hear, thank などが多いということが分かります。Observed collocate frequency の列の数値をクリックすると、その当該のコロケーション(候補語)の実際の用例を見ることができます。Lemma の列の単語と品詞をクリックすると、詳細な統計値と各位置で使われている割合が表示されます[2]。
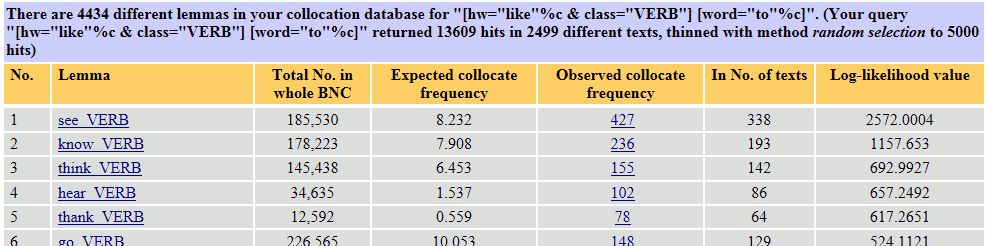
同様に、like に続く動名詞もコロケーション抽出機能で簡単に調べられるといいのですが、残念ながら、BNCweb のコロケーション抽出機能では、「全ての動詞の -ing 形」という条件を付けて、like に続く語を抽出することができません。なぜならば、[and/or tag:] に動詞の -ing 形に当たる選択肢がないからです。そのため、{like}_{V} で検索をして、コロケーション抽出機能を使ってその1語右の位置の -ing 形動詞を抽出するといったことはできません。(ただし、8節で紹介する別の検索方法で調べることができます。)
| 7 | would like to do を除いた like to do のみを検索したい |
(この節では、少し高度な検索の仕方を扱います。コーパス初心者の方は、途中の検索方法についての詳しい説明は読み飛ばして、検索結果だけを見ていただければ十分です。)
「like+to+動詞」に対応する {like}_{V}␣to␣_{V} を検索した結果をよく見てみると、would like to do での使用例が多いことが分かります。
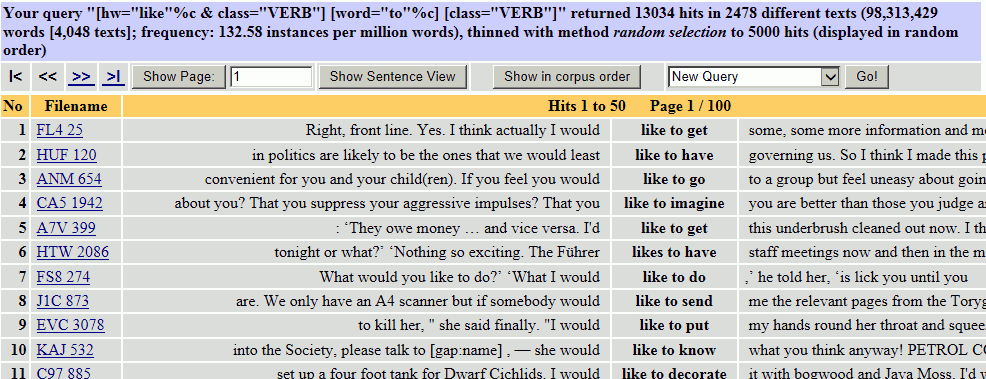
今回は「〜するのが好きだ」という意味での「like+to+動詞」を調べるのが目的ですので、would like to do は除外して考えたいところです。前に would がある用例は無視しながらひとつひとつ見ていくということも可能ですが、手間と時間がかかりすぎます。like の直前の would を避けて検索する方法はないのでしょうか。
例えば、「like の直前に代名詞が来ているもの」という形で検索するということも考えられます。これは、_{PRON}␣{like}_{V}␣to␣_{V} で検索できます[3] が、実際に検索してみると、“Would you like to do . . . ?” なども検索されますし、また like の直前に来るものは本来名詞(句)であってもよいはずであるのに、それまで排除されてしまうという問題があります。

このような場合に利用するのが CQP です。CQP(corpus query processor)は BNCweb のシステムの背後で使われている検索システムで、BNCweb で行う検索は、実は全てこの CQP の書式に自動的に変換された上で検索されています。検索結果の画面上部に表示されている Your query "〜" returned . . . の 〜の部分に表示されているのが、変換された CQP の書式です。基本的な語句の検索などを行う場合には CQP を使う必要はありませんが、一部の複雑な検索や前後の環境を指定した検索は直接 CQP の書式で書かないと行うことができません。今回のように、「直前に would がない like+to+動詞」はこの CQP の書式で指定することができます。
{like}_{V}␣to の検索結果で表示される CQP の書式([hw="like"%c & class="VERB"] [word="to"%c])の前に「would 以外」を表す [word!="would"%c] を追加した
[word!="would"%c]␣[hw="like"%c␣&␣class="VERB"]␣[word="to"%c]
[4]
が「直前の1語の位置に would 以外の語が来る」という条件付きでの「like+to」に対応します。これで検索してみましょう。
CQP の書式で検索するには、初期画面の検索ボックス下の [Query mode:] を CQP syntax に変更する必要があります。
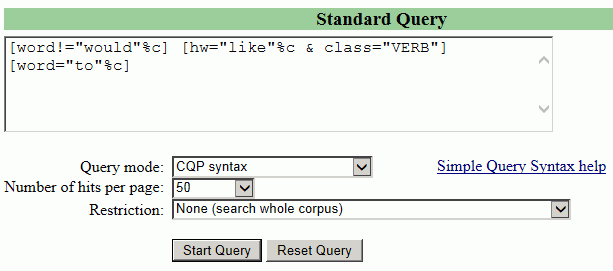
この検索の結果、確かに直前に would が来るものは排除されましたが、“I should like to” や “I'd like to” や “Would you like to” などの用例があり、まだ「〜したい」の用例が多いということが分かります。
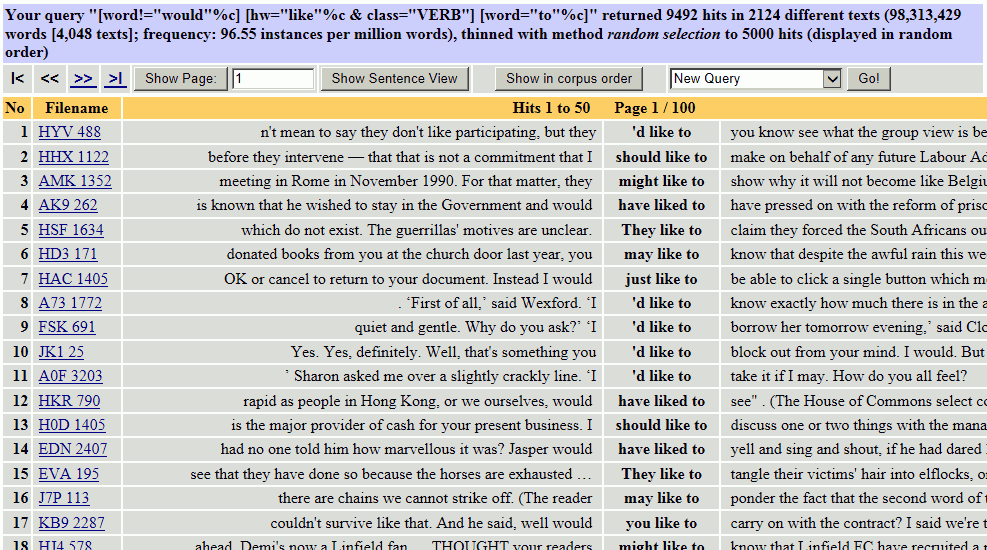
そこで、もう少し制限を強くしてみましょう。like の1語左の位置にも2語左の位置にも、would, should, 'd のいずれも来ないようにします[5]。これを表す CQP の書式が次のものです。
[word!="(would|should|'d)"%c]␣[word!="(would|should|'d)"%c]␣[hw="like"%c␣&␣class="VERB"]␣[word="to"%c]
[6]
これで前に would, should, 'd が来るものはかなり排除できました。さらに検索結果が4,203件となり、5,000件を超えていないため、全ての用例を見ることができます。

それでも、検索結果をよく見ていくと、「〜するのが好きだ」という意味の「like+to+動詞」だけでなく、「〜したい」という意味の用法が見られます。例えば、上の画面の最初の例である What else do you like to do?(KDS 1873)は、Do you garden? と続くことからも「他には何をするのが好き?」と趣味を尋ねている文だと判断でき、今回調査対象としている「〜するのが好きだ」に当たる例だと言えます。しかし、そもそも普段の習慣的なことを言う場合には「〜するのが好きだ」と「〜したい」という意味の境界線はかなり曖昧になります。また、表示された文脈だけでは判断に迷う例も少なくありません。例えば上の画面の4番目の例である(I consider all my family equal.) I don't like to see a single one trying to outdistance another.(A6N 2370)は、「(家族の)誰一人でも他の人に差をつけようとしているのを見るのは嫌だ(=好きでない)」とも「見たくない」とも考えられます。また、上の画面の8番目の例である So some people like to think that the point has moved one place to the right.(JJS 180)は、「数を10倍にした時には数字が全部左に1桁ずれるが…」という文脈で[7]、「小数点が右に1つずれたと考える方を好む人もいる」とも「…と考えたい人もいる」とも取れます。
コーパスでは語句の形や前後の語句の制限に基づく検索は簡単にできるのですが、ここでの例のように、意味が関係する検索はコーパス検索だけでは限界があり、詳細な分析をするためには人の目で一例ずつ検討していく必要があります。
| 8 | 「like+to+動詞」の動詞部分と「like+動名詞」の動名詞部分の頻度を調べる |
前節で見たような問題はありますが、「like+to+動詞」と「like+動名詞」で動詞の使い分けに何らかの傾向があるのかを調べるという当初の目的に立ち返り、それぞれの動詞の頻度を見ておきましょう。まず「like+to+動詞」については、上記の検索結果が表示されている状態から、6節と同じ方法で、直後の動詞のコロケーションを抽出します。
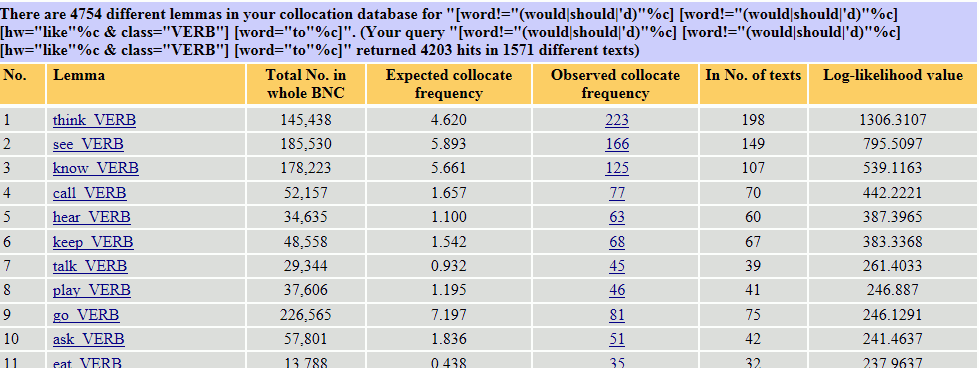
知覚やコミュニケーションに関する動詞が多いように思われますが、用例を実際に見ていくと、特に think や know の用例では、「would や should が先行しない like+to+動詞」が「〜するのが好きだ」という好悪ではなく、「〜したい」という意志や願望を表していると考えた方がよさそうなものが多く見られます。
次に「like+動名詞」についてですが、この動名詞部分の頻度は、近接検索(Proximity queries)[8] という方法を使って、
_V?G<<1<<{like}_{V}
で「直前の1語の位置に like がある動名詞」を検索することで調べることができます。これで検索をすると、動名詞部分のみがキーワードとなる検索結果が表示されます。そこから、ドロップダウンリストで Frequency breakdown [9] を選択し、 をクリックすると、当該の動名詞の頻度順リストが表示されます。

like の後に来る動名詞としては being, doing, going, having が多いということが分かります。being の用例をさらに詳しく見てみると、そのおよそ半分で being の後に過去分詞が続いていて、受動態の動名詞が多いということが分かります。さらに、「like+being+過去分詞」の用例は、そのほとんどが否定文で、「…されるのが好きではない」という意味の用例です。
「would や should が先行しない like+to+動詞」と「like+動名詞」の動詞・動名詞部分の頻度データはこれで入手できました。この2つのデータを見比べると、やはり何らかの使い分けの傾向はありそうです。実際にこの2つのパターンの違いを考える場合は、7節で見たような問題点を踏まえた上で、用例を丁寧に見ていくことが必要になりますが、今回はそこまでは踏み込まないでおきます。
| 9 | 使用例の分布を見る |
これまでは検索結果のそれぞれの文の出典にまでは注意を払いませんでしたが、検索した語句が話し言葉と書き言葉のどちらで多く使われるのか、どのジャンルで使われることが多いのか、どのような発話者の属性(性別・年齢・社会階層など)に多く使用例が見られるのか、といったことも重要な情報です。BNCweb では、そのような使用例の分布を調べることもできます。
例として、「like+動名詞」の使用例の分布を調べてみましょう。{like}_{V}␣_V?G で検索し、検索結果の画面で、ドロップダウンリストで Distribution を選択し、 をクリックします。すると、次の図のように、「like+動名詞」の使用例の分布状況の概観が表示されます。
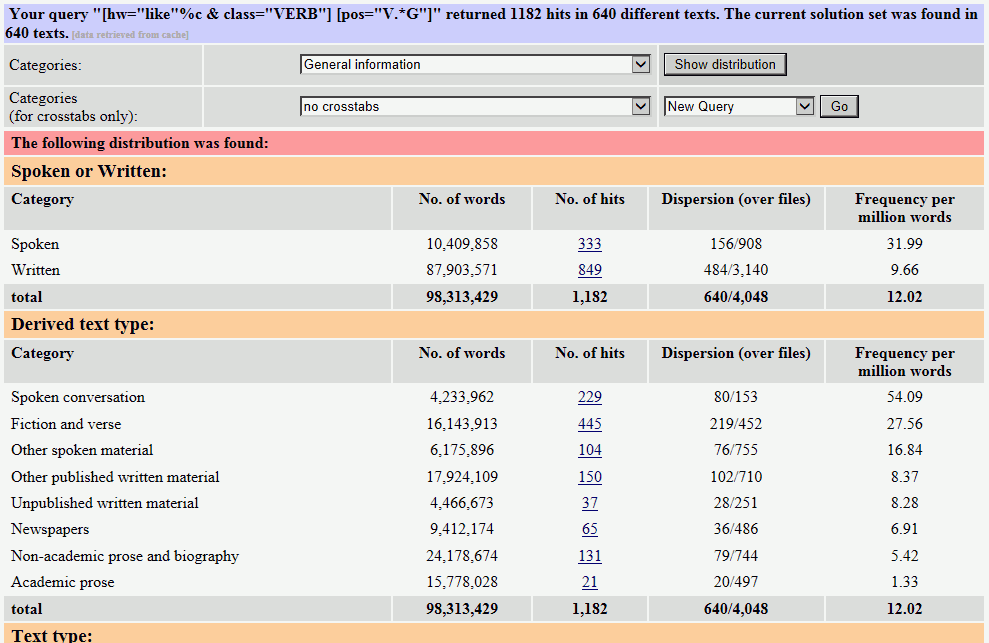
話し言葉の頻度(100万語あたり31.99回)の方が、書き言葉の頻度(100万語あたり9.66回)よりも高いことが分かります。
今度は「like+to+動詞」の使用例の分布状況を調べてみましょう。まずは8節の方法で、Query mode を CQP syntax に変更し、
[word!="(would|should|'d)"%c]␣[word!="(would|should|'d)"%c]␣[hw="like"%c & class="VERB"]␣[word="to"%c]␣[class="VERB"]
で検索します。それから、検索結果画面で、ドロップダウンリストで Distribution を選択し、 をクリックします。
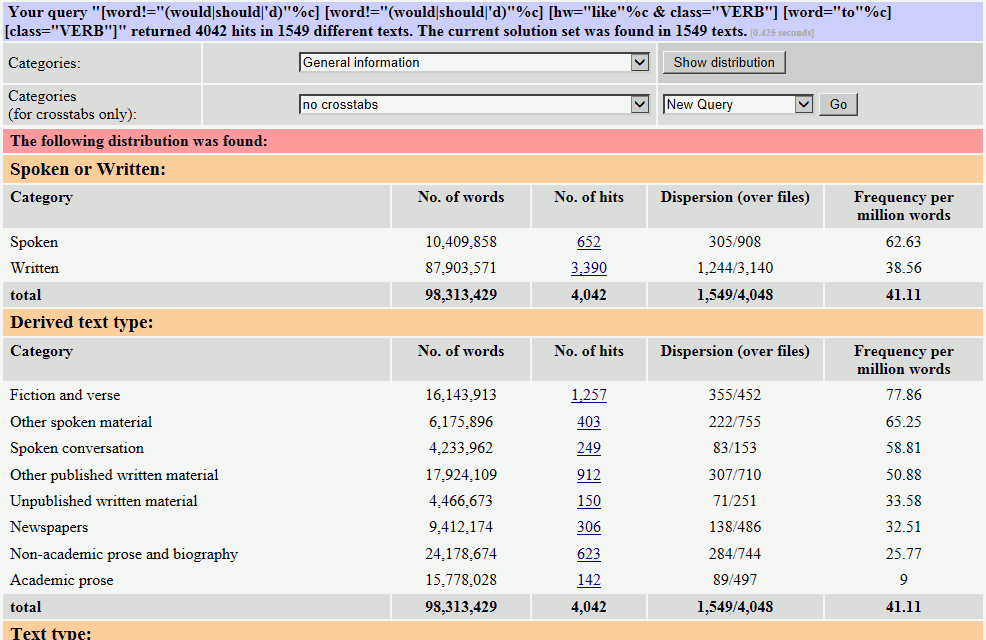
こちらも、話し言葉の頻度(100万語あたり62.63回)の方が、書き言葉の頻度(100万語あたり38.56回)よりも高いことが分かります。ただし、この両者の結果が意味のある違いであるのかどうかは、統計的に分析するなど、別途検討が必要です。
また、「like+to+動詞」と「like+動名詞」の結果の違いを分析するためには、このような頻度データだけでなく、それぞれがどのような場面で使われる表現なのかという言語使用の原点に立ち返らなくてはいけません。「〜するのが好きだ」という表現自体、会話などの話し言葉で使われるのが普通で、話し言葉の方が頻度が高いのは当然だと考えられます。(書き言葉での頻度が予想外に高いと思われるかもしれませんが、より詳細な内訳を見ると、どちらも Fiction and verse のカテゴリーでの使用頻度が高く、小説の会話部分などでの使用が多いということが予想されます。)また、BNC のデータでは、そもそも動詞の like の頻度は話し言葉の方が書き言葉のおよそ3.6倍であるということも考慮しなくてはいけないでしょう。
| 10 | まとめ |
前回と今回の2回にわたり、BNCweb の基本的な使い方を一通り見てきました。その過程で、「こうすれば目的のことが調べられる」という答えを最初から紹介するのではなく、あえて試行錯誤しながらコーパスを検索するプロセスを再現してみました。それによって実際のコーパス検索のイメージもつかめたのではないかと思います。また、頻度のようにコーパスを使って初めて分かることもあれば、形では弁別できない表現の意味のようにコーパス検索だけでは限界があることもあるということも見ました。
この記事では紹介しませんでしたが、BNCweb には、BNC のデータの中から、任意のサブコーパス(テキストのジャンルや発話者の性別・年齢を限定したデータ)を作ったり、サブコーパスの中での語彙頻度リストを作ったり、サブコーパス間の比較によってそれぞれのキーワード(候補)を抽出したりする機能もあります。また、検索結果やリストは、ダウンロードして、自分でさらに加工したり他の用途に利用したりすることもできます。
この記事がきっかけとなって、BNCweb を使い始め、そして今後本連載で紹介される様々なコーパスを使い、ことばに関する様々なことをご自身で調べられるようになっていただければ幸いです。
|
〈著者紹介〉 石井 康毅(いしい やすたけ) 成城大学社会イノベーション学部准教授。専門は認知言語学、コーパス言語学、辞書学。英語の前置詞の意味の広がり、コロケーション、コーパスからの情報抽出などに興味・関心がある。共著書に『道を歩けば前置詞がわかる』(くろしお出版)、『連関式英単語 Linkage』(Z会)、『UNICORN English Communication 1』、『UNICORN English Expression 1』(ともに検定教科書、文英堂)がある。執筆に参加した辞書に『オーレックス英和辞典』(旺文社)、『エースクラウン英和辞典』(三省堂)などがある。 |
Data cited herein have been extracted from the British National Corpus, distributed by Oxford University Computing Services on behalf of the BNC Consortium. All rights in the texts cited are reserved.
〈注〉
[1] ただし、この機能は「検索語句の1語左の位置の動詞」や「検索語句の1〜3語右の位置で使われている名詞」などの条件で、単に近くの単語を機械的に集計するものに過ぎません。したがって、この機能で得られるデータは、「慣習的に使われる、頻度の高い結びつき」という厳密な意味でのコロケーションとは必ずしも一致しない場合もあります。
[2] 位置情報については、今回は 1 Right - 1 Right 、つまり直後の1語の位置のみを指定しているので特に有益な情報が得られるわけではありませんが、例えば1 Right - 3 Right 、つまり1語右の位置から3語右の位置までを範囲とした場合には、それぞれの位置で当該の単語が使われている割合が表示されます。その状態で Distance の列の数値をクリックすると、それぞれの位置ごとの用例を見ることができます。
[3] {PRON} は代名詞に対応する品詞指定記号です。
[4] hw は原形(辞書などでの「見出し語」; headword)、%c は大文字(upper case)と小文字(lower case)の区別をしないということ、class は品詞、word は語形を表しています。「!=」は不等号(≠)に当たる記号です。
[5] BNC では 'd や 's や n't などの縮約形は独立した1つの単語として品詞タグが付けられています。
[6] CQP では、(A|B) は A または B ということを表します。ここで使っている [word!="(would|should|'d)"%c] は「would, should, 'd のいずれでもない単語」ということを表します。
[7] ランカスター大学で提供されているこの BNCweb の無料サービスでは各用例の文脈を広げて見ることはできませんが、例えば BYU-BNC(http://corpus2.byu.edu/bnc/)ではもう少し文脈を広げて見ることができます。
[8] 検索初期画面にリンクがある Simple Query Syntax help に、少しではありますが説明と例があります。
[9] Frequency breakdown はキーワードとなっている部分の頻度順のリストを得る機能です。
|
関連書籍 |
|
キーワードで書籍検索 コーパス corpus 認知言語 |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |