

実践で学ぶ コーパス活用術 |
|
5 小林 雄一郎 言語統計の基礎 (前編) ――頻度差の検定―― |
© (WT-shared) Matthew 6476 |
この連載では、いくつかのコーパスを使って、言語データを量的に分析する方法を学んできました。例えば、第3回の「英語コーパス体験ツアー―BNCweb を検索してみる―(後編)」では、like+動名詞に関して、「話し言葉の頻度(100万語あたり31.99回)の方が、書き言葉の頻度(100万語あたり9.66回)よりも高い」ことが示されています。この結果を見ると、「like+動名詞という表現は、書き言葉と話し言葉の間に、大きな頻度の差が見られる」、あるいは、「like+動名詞は、話し言葉に顕著な表現である」と感じるかもしれません。しかし、どれくらいの頻度差があれば、「大きな」差があると言えるのでしょうか。上記の BNCweb の例では約3倍の頻度差がありましたが、もし2倍だったらどうでしょうか。何倍以上の差を「大きな」差と見なすかは、人によって異なるかもしれません。
そこで今回は、複数の言語データの間の頻度差が意味のある差なのか、それとも偶然によるものなのかを推測する方法を紹介します(統計学では、この「意味のある差」のことを「有意差」と言います)。具体的には、「書き言葉」と「話し言葉」というレジスター間における as if と as though の頻度に関する分析事例を紹介します。[1] これらの表現は、ともに「まるで 〜 であるかのように」という意味だとされており、例えば、『リーダーズ英和辞典』(第3版)にも「as though=as if」と書かれています。同様に、様々な表現に関してレジスターごとの使用頻度を網羅的に比較している Longman Grammar of Spoken and Written English でも、as if と as though は区別されていません。しかしながら、2つの表現の意味が同じであることと、それらの表現が同じような状況で使用されることは別です。以下、仮説検定という統計手法を用いて、書き言葉と話し言葉における as if と as though の頻度差を分析してみます。
| 1 | 仮説検定の考え方 |
コーパス言語学で頻度の差を調べる場合、仮説検定と呼ばれる方法がよく用いられます。ここで、仮説検定の手順について、簡単に説明します。データ調査では、当該データ全てを調べる場合と、その一部のみを対象とする場合があります。統計学では、この「対象となるデータ全て」を母集団と言い、「その一部」を標本と言います。コーパス言語学では、書き言葉と話し言葉における語彙頻度の差を調べたり、母語話者と非母語話者による言語的特徴を比較したりすることがあります。しかし、「現代英語の書き言葉」や「英語の非母語話者」という母集団全体を調査すること(全数調査)は事実上不可能です。そこで、すでに公開されているコーパスを利用したり、特定の国や地域に住む非母語話者のデータを収集したりすることになります(標本調査)。
今回は、COCA というコーパスを用いて、書き言葉と話し言葉における as if と as though の頻度の差を調査します。その後、仮説検定を用いて、標本(コーパス)から得られた結果を母集団(現代アメリカ英語)の性質として一般化できるかどうかを検討します。今回の分析では、「書き言葉」という要因と「話し言葉」という要因があると考え、それぞれのレジスターで as if と as though の頻度が異なるという仮説を立てます。そして、この仮説の確からしさを統計的に判断します。
仮説検定では、最初に2つの仮説を立てます。
そして、統計学では、最初に要因による差はないという仮説(帰無仮説)を検証し、その確からしさを求めます。その結果、一定の確からしさが確認された場合には、帰無仮説を採択し、「要因による差はない」と結論します。逆に、確からしさが確認されない場合には、帰無仮説を棄却し、「要因による差がある」という対立仮説を採択します。以上が仮説検定の手続きです。[2]
なお、帰無仮説の確からしさを検証するにあたっては、標本から実際に得られた頻度(実測値)と「差がない」と仮定した場合の理論上の頻度(期待値)を比較し、両者における頻度の違いが偶然によるものかどうかを確率的に判断します。
| 2 | COCA を使ったレジスター分析 |
では、COCA(Corpus of Contemporary American English)を使って、実際にレジスター間の頻度差を調べてみましょう。COCA とは、1990年以降のアメリカ英語(約4億5000万語)を集めたコーパスです。このコーパスは、ユーザー登録をすれば、以下の URL から誰でも無償で利用することが可能です。
ユーザー登録をして、トップページからログインすると、以下のような画面が表示されます。
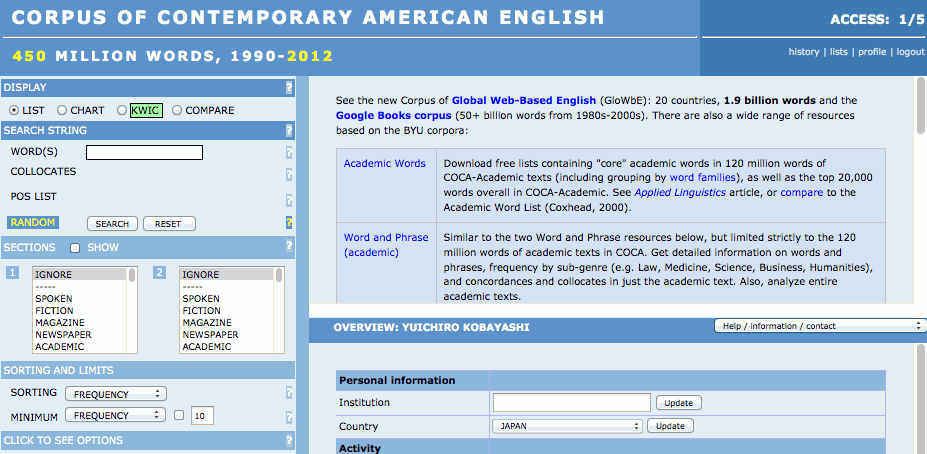
そして、この画面の左上にある SEARCH STRING の WORD(S) のボックスに検索したい語(句)を入れて、その下にある のボタンを押すと、検索結果が返ってきます。また、SEARCH STRING の下にある SECTIONS の 1 のメニューを使って、特定のレジスターのみを検索することもできます。
ここでは、話し言葉(SPOKEN)と学術散文(ACADEMIC)における as if と as though の頻度を比較してみましょう。[3] まず、SEARCH STRING の WORD(S) のボックスに as if と入力し、SECTIONS の 1 から SPOKEN を選び、 のボタンを押します(それ以外の設定はデフォルトのまま)。すると、COCA の話し言葉における as if の頻度が4785回であることが分かります。[4]
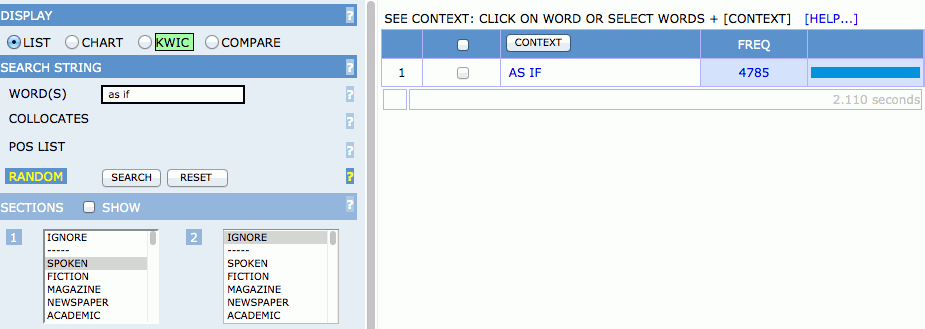
同様に、WORD(S) のボックスに as though と入力して検索すれば、話し言葉における as though の頻度が分かります。しかし、2回検索しなくても、as if|though で検索すれば、1回の検索で2つの表現の頻度が得られます( | は、or を表す特殊記号で、この検索式は「as の直後に if または though が生起する場合」という意味になります)。
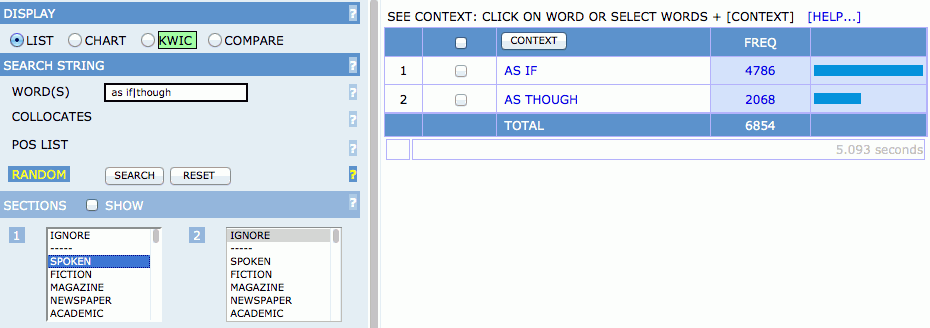
さらに、SECTIONS の 1 で SPOKEN を選択したまま、2 で ACADEMIC を選択すると、話し言葉と学術散文における as if と as though の頻度を一度に検索することができます。
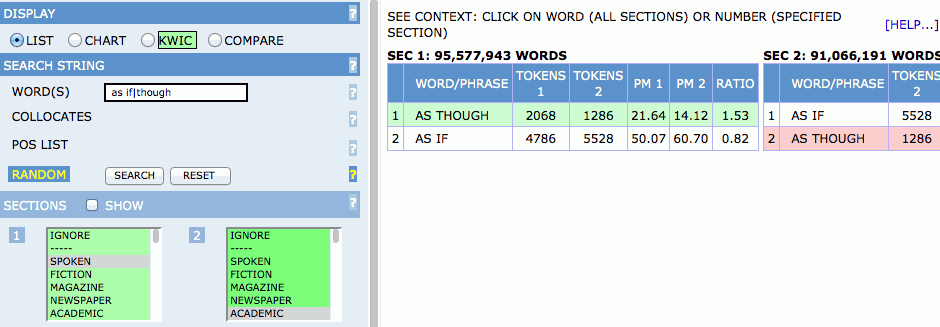
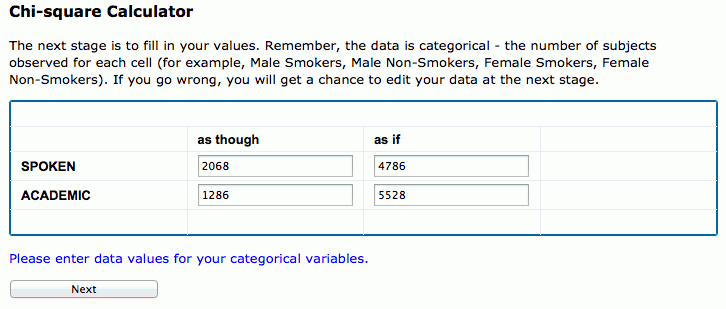
検索結果として、画面の右側に2つの集計表が表示されますが、内容的には同じものですので、ここでは左側の表を見てください。表中の TOKENS 1 と TOKENS 2 は、検索時に SECTIONS の 1 と 2 で選択したレジスター、つまり、話し言葉と学術散文に対応しています。これを見ると、話し言葉における as though と as if の頻度がそれぞれ2068回と4786回で、学術散文における頻度がそれぞれ1286回と5528回であることが分かります(ちなみに、表中の PM は、100万語あたりの相対頻度を表しています)。
この検索結果によると、as though が学術散文よりも話し言葉で多く使用され、as if が話し言葉よりも学術散文で多く使用されています。ここで、前節の母集団と標本について思い出してください。統計学的には、COCA は、現代アメリカ英語という母集団から抽出された標本ということになります。従って、標本から得られた結果を母集団の性質として一般化するには、仮説検定を行う必要があります。ここでの帰無仮説は「現代アメリカ英語において、話し言葉と学術散文では、as though と as if の頻度に差はない」で、対立仮説は「現代アメリカ英語において、話し言葉と学術散文では、as though と as if の頻度に差はある」となります。
| 3 | カイ二乗検定 |
コーパスにおける頻度の差を検定する場合、カイ二乗検定という手法がよく用いられます。この手法は、SPSS や R といった統計ソフトはもちろんのこと、Excel で行うこともできます。また、ウェブ上にも、多くの利用可能なサービスが存在します。ここでは、Easy Chi-square Calculator というサイトを使ってみましょう。
http://www.socscistatistics.com/tests/chisquare/Default2.aspx
上記の URL にアクセスしたら、まず、行方向に検索語句(as though, as if)、列方向にレジスター(SPOKEN, ACADEMIC)を入力し、 を押します。
次に、4つのセルに COCA から得られた頻度を入力し、 を押します。この際、100万語あたりの相対頻度(PM)ではなく、生の頻度(TOKENS)を入力することに注意してください。
すると、有意水準(Significant Level)をいくつにするかを問われます。有意水準とは、検定の結果として得られた「有意差あり」という判定が間違っている確率をどれくらい許容するかという基準です。検定は、あくまで確率を用いた推測であり、何らかの誤りを含んでいる場合もあります。そして、有意水準を甘くすると、「本当は差がないのに差がある」と判定する誤り(第1種の誤り)の可能性が増し、逆に有意水準を厳しくすると、「本当は差があるのに差がない」と判定する誤り(第2種の誤り)の可能性が増します。従って、有意水準をいくつにするかは、分析者自身が設定するようになっています。ここでは、デフォルトの0.05(5%)のまま、 ボタンを押します。

すると、画面に青字で、カイ二乗検定の結果が表示されます(The Chi-square statistics is 235.592. The P value is 0. The result is significant at p ‹ 0.05.)。これを見ると、5%の有意水準で有意差がある(significant)ことが分かります。つまり、「現代アメリカ英語において、話し言葉と学術散文では、as though と as if の頻度に差はない」という帰無仮説が棄却され、「現代アメリカ英語において、話し言葉と学術散文では、as though と as if の頻度に差はある」という対立仮説を採択します。
COCA を用いて調査した結果、as though は話し言葉に顕著な表現で、as if が学術散文に顕著な表現であることが確認されました。この分析はあくまで一例に過ぎません。今回取り上げた as though と as if に関して、話し言葉と学術散文以外の様々なレジスター間の違いを検証するのもよいでしょうし、年代による頻度の差を調査することも可能です。また、COCA と BNCweb を使って、アメリカ英語とイギリス英語の違いを調べることもできますし、学習者コーパスと呼ばれる非母語話者のデータと比較することも興味深いでしょう。
もちろん、仮説検定の結果は、あくまで統計的な推測に過ぎず、統計学的な有意差がそのまま言語学的な有意差を表すとは限りません。そこで、特定の言語現象に関して確定的なことを述べるには、調査対象とする表現がどのような文脈で使われているのかを仔細に検討する必要があるでしょう。言語研究にとって、コーパスや統計に基づく量的分析と、分析者の知見や言語理論に基づく質的分析のいずれかだけでは不十分であり、両者がバランスよく融合されている必要があります。
言語統計の前編はここまでです。今回は、2つの言語データにおける頻度差を検定する方法を見てきました。後編では、コロケーション研究を例に、複数の語の結びつきの強さを調べる方法を紹介します。
|
〈著者紹介〉 小林 雄一郎(こばやし ゆういちろう) 日本学術振興会特別研究員 PD。専門は、コーパス言語学、計量文献学、テキストマイニング。統計学や自然言語処理の技術を用いた言語研究、特に英作文の自動採点、文学作品の著者推定などに関心がある。共著書に、『言語研究のための統計入門』(くろしお出版)、『英語教育学の実証的研究法入門』(研究社)、『英語学習者コーパス活用ハンドブック』(大修館書店)、『R で学ぶ日本語テキストマイニング』(ひつじ書房)、Twenty years of learner corpus research: Looking back, moving ahead(Presses universitaires de Louvain)などがある。 |
〈注〉
[1] 「レジスター」とは、コーパス言語学や社会言語学などで使われる用語で、特定の場面や状況に固有の言語変種のことを指します。ここでは、「書き言葉」や「話し言葉」、あるいは、書き言葉の下位分類である「小説」や「新聞」などのことを表していると考えてください。
[2] 仮説検定を行う場合、何らかの「差がある」ことを知りたいことが多いにもかかわらず、「差がない」という仮説を最初に立てるのを不思議に思うかもしれません。「差がある」という仮説は、「大きな差がある」、「中くらいの差がある」、「小さな差がある」のように無限に考えられ、それら全てを検討するのは不可能に近いでしょう。それに対して、「差がない」という仮説は、非常にシンプルです。従って、「差がない」という仮説を最初に立てて、それが正しいかどうかを調べるというアプローチを選ぶのです。
[3] 「学術散文(academic prose)」は、コーパスに基づくレジスター研究の用語です。学術散文は書き言葉の中でも(新聞や小説と比べて)非常に書き言葉らしい特徴を持つレジスターであるため、ここでは、学術散文を書き言葉の代表と見なし、分析対象とします。
[4] COCA は、随時データが更新されているため、今回掲載した検索結果と異なる結果が表示される場合もあります。また、検索システムの更新も頻繁に行われています。検索がうまくいかない場合、あるいは、より高度な検索方法を知りたい場合は、WORD(S) のボックスの右にある ? をクリックすれば、様々な検索方法に関するヘルプを参照することができます。
|
関連書籍 |
|
キーワードで書籍検索 コーパス corpus リーダーズ英和辞典 |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |