

実践で学ぶ コーパス活用術 |
|
6 小林 雄一郎 言語統計の基礎 (後編) ――共起尺度―― |
© (WT-shared) Matthew 6476 |
前編では、カイ二乗検定を用いて、COCA の話し言葉と学術散文における as if と as though の頻度差を分析する方法を紹介しました。後編では、コロケーション研究を例に、ある単語と別の単語の結びつきの強さ(共起強度)を測る方法を紹介します。
今回の分析には、BNCweb を使います。その理由は、ほかの検索ツールよりも多くの共起強度に関する指標(共起尺度)が利用可能だからです。[1] BNCweb の使い方については、適宜、第2〜3回の「英語コーパス体験ツアー――BNCweb を検索してみる」も合わせて参照してください。
| 4 | 共起尺度としての頻度 |
突然ですが、political という語の直後に生起する全ての語の中で、最も頻度の高い語は何でしょうか。なお、この調査に用いるコーパスは、BNCweb(全体)とします。
その答えを知るために、まずは、BNCweb のサイトにアクセスし、検索ボックスに political と入力してから、 のボタンを押しましょう(その他の設定はデフォルトのまま)。
上記の検索を行うと、political という語は、BNC 全体の中の1759テキストで使われており、その頻度が合計で30098回であることが分かります。そして、political のコロケーションを調べるには、New Query ∨ と表示されているメニューから Collocations... を選択し、右隣の というボタンを押します。すると、BNC Collocation Settings という画面が表示されますが、全てデフォルトのまま、 のボタンを押します。

その結果、political のコロケーションを集計した画面が表示されます。画面上部を見ると、コロケーションを集計する範囲(Collocation window span)が検索語(political)の前後3語ずつであり、2語の結びつきの強さを測る尺度(Statistics)として Log-likelihood(後述)が使われていることが分かります。
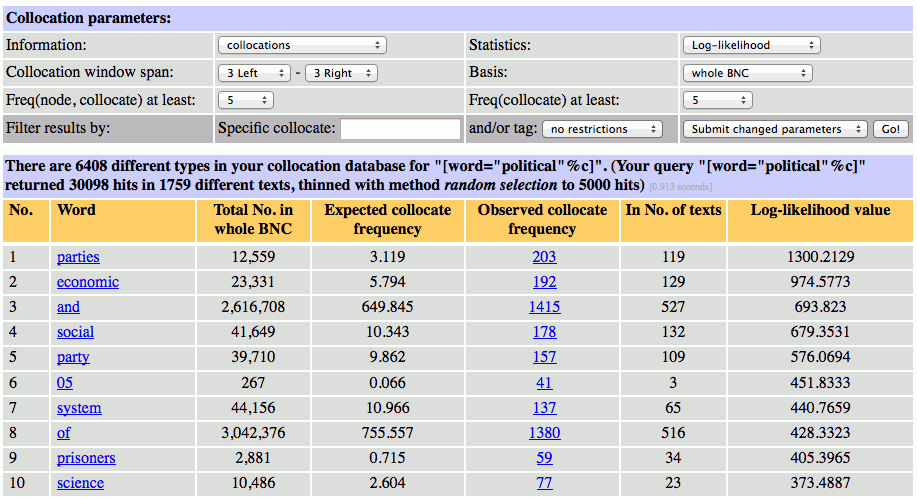
先ほどの問いは、「political という語の直後に生起する全ての語の中で、最も頻度の高い語」は何かというものでした。そこで、Collocation window span を 1 Right - 1 Right(右1語から右1語まで、つまりは検索語の直後に生起する語のみ)とし、Statistics を Rank by frequency(頻度順)としてから、再び というボタンを押します。

さて、「political という語の直後に生起する全ての語の中で、最も頻度の高い語」は何だったでしょうか。答えは、and でした。

この答えを聞いて「何だ」とがっかりした読者もいるでしょうし、「どうして」と疑問に思う読者もいるかもしれません。おそらく、多くの読者は、「political の直後に生起する語」と言われれば、2位の parties や3位の system のような名詞をイメージしたのでしょう。しかし、BNC において、political の直後に最も高い頻度で生起する語は、紛れもなく and なのです。具体的に and がどのように用いられているかを見るには、Word という列の and という語のリンクから、次の画面の Distance の列の1というリンクをたどります。

実際の使用例を見ると、political and historical, political and economic, political and social のような表現が目につくでしょう。これはこれで面白いと思う読者もいるかもしれません。しかし、コロケーション調査として、この分析は不十分であると言わざるを得ません。ここで、2つ前の図を見返してみてください。BNC 全体における political and の頻度(Observed collocate frequency)は299回です。しかし、見逃してはならないのは、BNC 全体における and の頻度(Total No. in whole BNC)が2616708回と極めて高い点です。このように極めて高い頻度を持つ語は、コーパスのいたるところに生起し、非常に多くの語と共起します。言い換えると、and は、political と「だけ」強い結びつきを持っているわけではなく、コーパス中の様々な語と万遍なく結びついている語であると言えます。このように、共起の強さを頻度だけで測るという方法には、明らかな限界があります。次節以降、BNCweb で利用可能な共起尺度を紹介していきます。なお、個々の尺度の詳しい計算方法より、具体的にどんな特徴を持っているかに重きを置いた説明をします。
| 5 | T-score |
まず、T-score は、t 検定という仮説検定の方法を利用した尺度です(検定については、前回の「言語統計の基礎(前編)――頻度差の検定」を参照してください)。この尺度は、2つのコロケーション(例えば、as if と as though)のどちらがより有意な(≒重要な)コロケーションなのかを調べる場合などに用いられます。以下は、Statistics メニューで T-score を選択して、BNC における political の直後に生起する共起語を抽出した結果です。
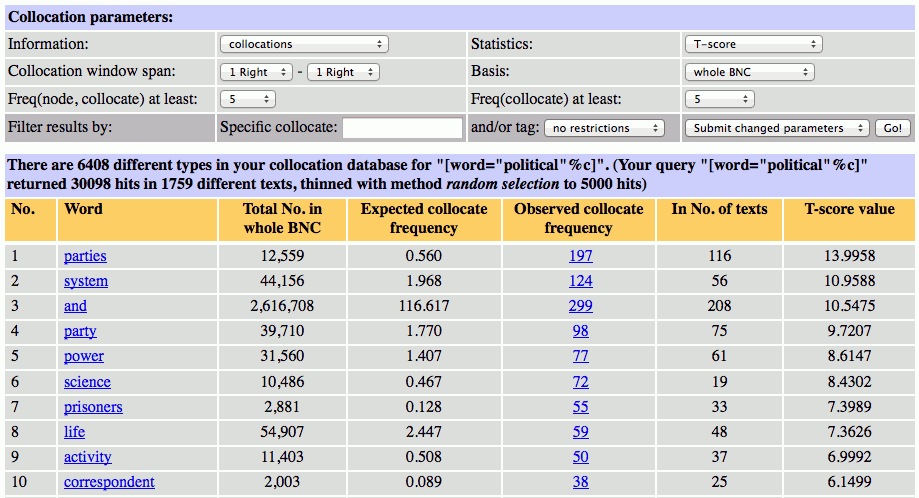
T-score の結果を先ほどの Rank by frequency の結果と見比べてみると、上位10語に含まれる語のうち、9語が共通して抽出されています(Rank by frequency にあったカンマがなくなった代わりに、T-score では correspondent がランクイン)。このようにT-score は、多くの場合に、Rank by frequency とよく似た結果を返すことが知られています。
| 6 | Log-likelihood |
Log-likelihood は、コーパス言語学で広く用いられている手法で、BNCweb のコロケーション抽出機能でデフォルトとして設定されている尺度です。Log-likelihood も、T-score と同様に、仮説検定の方法を利用した尺度です(対数尤度比検定という検定に基づいています)。以下は、Statistics メニューで Log-likelihood を選択して、BNC における political の直後に生起する共起語を抽出した結果です。
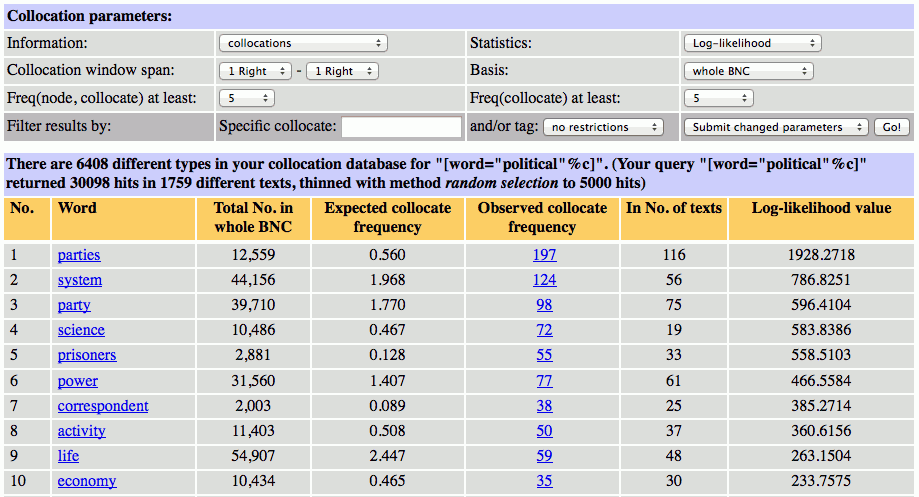
Log-likelihood の結果も、Rank by frequency の結果とよく似ています(上位10語に含まれる語のうち、8語が共通して抽出)。しかし、Rank by frequency の上位にランクインしていた and とカンマがなくなり、全て「political+名詞」という組み合わせになりました。このように、Log-likelihood は、ある程度高頻度の組み合わせでありながら、元々コーパス中での頻度が極めて高い機能語や記号との組み合わせを排除する傾向を持っています。このため、コーパスに基づく語法研究などで使われることが多い尺度です。
| 7 | Mutual information |
Mutual information は、情報理論から生まれた尺度で、ある単語が与えられたときに、どの程度、その共起語を予測できるかという考え方に基づいています。ちなみに、Mutual information は、COCA のコロケーション抽出機能で(頻度以外に)唯一利用可能な共起尺度でもあります。以下は、Statistics メニューで Mutual information を選択して、BNC における political の直後に生起する共起語を抽出した結果です。
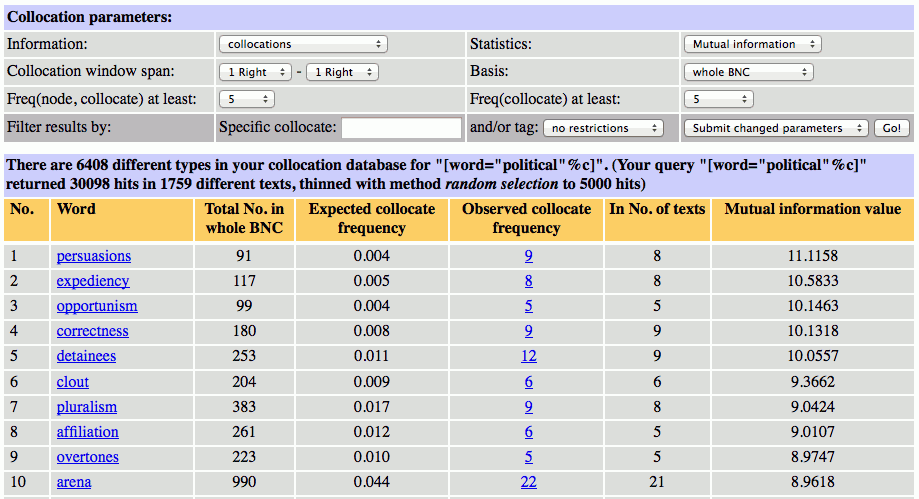
この結果を見ると、Rank by frequency はもとより、T-score や Log-likelihood の結果とも大きく異なっていることが分かります。Mutual information を用いると、ほかの尺度と比べて、低頻度の共起語が上位にランクインすることが知られています。そのため、この尺度は、比較的珍しい語の組み合わせを抽出するので、特定の作家の文体を研究したり、特定のレジスター(例えば、医学英語)に特徴的な表現のリストを作成したりするのに使われています。また、あまりにも低頻度の語を除外したい場合は、共起語として抽出する語の最低頻度(BNCweb では、Freq (collocate) at least で設定可能)を任意の数まで引き上げるとよいでしょう。
| 8 | その他の共起尺度 |
以上、頻度以外に、T-score, Log-likelihood, Mutual information という3つの共起尺度を比較してきました。それらの特徴を大まかにまとめると、T-score が高頻度な共起表現を抽出しやすい一方、Mutual information が低頻度な共起表現を抽出しやすく、Log-likelihood がその中間(ただし、どちらかと言えば、T-score に近い)です。可能な限り、複数の尺度による抽出結果を見比べてみるとよいでしょう。
ちなみに、BNCweb には、これまで紹介してきたもの以外にも、Z-score, Dice coefficient, MI3 という3種類の尺度が実装されています。以下は、これらの尺度を用いて、BNC における political の直後に生起する共起語を抽出した結果をまとめたものです。
Z-score
Dice coefficient
MI3

これまでに見てきたものと同様、使用する尺度が変われば、その結果として抽出される共起語も変化します。これらの尺度に慣れないうちは、どれを使えばよいか迷ってしまうかもしれません(そして、どの尺度を使うべきかは、研究の目的やデータの性質によっても変化します)。そういう場合は、まず、コーパス言語学の分野で最もよく使われている Log-likelihood を検討してみるとよいでしょう。[2]
| 9 | まとめ |
前回と今回の2回にわたって、言語統計の基礎(の一端)を紹介してきました。いかがでしたでしょうか。仮説検定や共起尺度を使うことで、より客観的な言語研究を行うことが可能になります。また、この連載で紹介した手法はいずれも基本的なものですが、それだけに、分析者のアイデア次第で様々な研究に応用することができます。この記事をきっかけに、統計を用いた言語研究に関心を持っていただければ幸いです。
|
〈著者紹介〉 小林 雄一郎(こばやし ゆういちろう) 日本学術振興会特別研究員 PD. 専門は、コーパス言語学、計量文献学、テキストマイニング。統計学や自然言語処理の技術を用いた言語研究、特に英作文の自動採点、文学作品の著者推定などに関心がある。共著書に、『言語研究のための統計入門』(くろしお出版)、『英語教育学の実証的研究法入門』(研究社)、『英語学習者コーパス活用ハンドブック』(大修館書店)、『R で学ぶ日本語テキストマイニング』(ひつじ書房)、Twenty years of learner corpus research: Looking back, moving ahead(Presses universitaires de Louvain)などがある。 |
〈注〉
|
関連書籍 |
|
キーワードで書籍検索 コーパス corpus リーダーズ英和辞典 |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |