

実践で学ぶ コーパス活用術 |
|
18 三浦 愛香 学習者の話し言葉コーパスを使った語用論分析
(1) |
© (WT-shared) Matthew 6476 |
これまでの連載で、学習者コーパス(第9回、第10回)や話し言葉コーパス(第16回、第17回)が登場しましたが、今回から2回にわたり「学習者の話し言葉コーパスを使った語用論分析」をテーマとして扱います。
| 1 | 中間語用論: 語用論と学習者言語 |
中間語用論という分野をご存知でしょうか? 学習者が発話した言語を中間言語と言い、学習者の語用論的能力を検証する分野を中間語用論と呼んでいます。語用論の分野では、対話において話し手が発話した言葉が聞き手に与える影響を考察します。例えば、部屋の窓が開いており、風が入ってくるので寒く感じたとします。窓のそばに立っている人に、「窓を閉めてもらえますか?」と敬語を使って丁寧に頼むのと、「窓を閉めろ!」と命令するのとでは、聞き手が受ける印象は異なります。何かをお願いする時に、通常話し手は相手との衝突をできるだけ回避することを意識し、時と場合に応じて使う言葉の表現を変えます。また、「何だか寒いね。」と一言相手に伝えることで、間接的に「窓を閉めてほしい」という意志を伝えることもできます。つまり、言葉が持つ表層的な意味ではなく、時には話し手の意図を示す言外の意味も扱うのが語用論の分野です。中間語用論では、社会的に適切な発話を実現できるコミュニケーション能力を学習者がどのように習得するかを分析します。
| 2 | 語用論とコーパス |
これまでの連載では、コーパスにおいて語彙や文法項目がどのように使用されているのか、コンコーダンスラインで使われている意味やコロケーション等を確認しながら見てきました。コーパスを使った言語研究においては、コーパスから抽出された言語項目の頻度分析や統計的解析が主流です。
しかし、語用論の分析においては、避けて通れないのが、文脈に依存して発話者の意図を特定することです。前述のように、日本語では、何かをお願いする時に命令形を使うのは失礼な言い方になりますが、失礼だと判断する基準は、話し手や聞き手が属している社会の規範や規則や状況によって異なります。例えば、「危ない! よけろ!」と路上で車にひかれそうになった見知らぬご老人に命令形で怒鳴ったとしても、緊急時には失礼にはあたらないでしょう。このように、語用論的に分析するには、発話された言語項目がどのような文脈で使われているのかを一つ一つ目で見て判断しなくてはなりません。また、その表現が失礼かそうではないかと判断する際に、分析者の主観に頼らざるを得ない部分もあります。また、前述のように発話者の使用した言語の表層的な意味ではなく、言外の意味を推測する必要性のある事例もあるでしょう。
コーパス分析は、言語データからある特定の言語項目を抽出できますが、大量の用例を取り扱うことから、文脈から切り離した表層的な分析に留まる傾向があり、こうした語用論分析には適していないとされてきました。コーパスを活用した語用論分析は、非常に労力と時間を要するという難点があります。しかし、最近では、母語話者の直観に基づいて発話を分析してきた従来の語用論分析をコーパス分析が可能とする計量的な結果と融合させることで、語用論分析をより客観的に強化することができると提唱する研究者も出てきています。[1]
| 3 | The NICT JLE Corpus とは |
今回扱うコーパスは、The NICT JLE Corpus です。これは、日本語を母語とする英語学習者1,281名分の英語インタビューテストを書き起こしたものです。
| 3.1 | 入手方法 |
本コーパスの入手方法は以下の2つがあります。
● アルクの『日本人1200人の英語スピーキングコーパス』(和泉・内元・井佐原 2004)に付属の CD-ROM で提供されています。こちらは書籍付属の Analyzer という専用ツールでのみ閲覧や分析が可能です。今回の記事中の数値は全てこのツールを使って計測しています。ただし現在は絶版となっています。
● 2012年より、構築者である独立行政法人 情報通信研究機構(NICT)の提供する以下の Web ページによってテキストファイルとして無料で入手できるようになりました。
https://alaginrc.nict.go.jp/nict_jle/
| 3.2 | アノテーション(付与情報)とコーパスの構造 |
本コーパスには、言語データだけではなく、タグと呼ばれる言語に関する情報が付与されています。以下に、学習者の語用論能力を検証するうえで有用となるアノテーション(付与情報)を紹介します。
本コーパスは、アルクによる Standard Speaking Test(SST)を書き起こしたもので、試験官と受験者(学習者)の二人の対話が含まれています。試験官の発話の開始を <A> という文字列で示し、終了を </A> で示しています。この文字列をタグと言います。また、受験者の発話には開始の <B> と終了 </B> のタグを付与しています。これらのタグがあることで、特定のタグで区別されたデータを任意に抽出することが可能になります。
SST には以下の表のように5つのステージがあり、各ステージやタスクごとにタグを使って言語データを区別しています。ステージ2 〜 4のフォローアップというのは、試験官が受験者に各ステージで実施したタスクの内容について質問をする、短い雑談の時間のことです。
</stage 1>
2 1枚のイラストに関する描写や質問に答える
フォローアップ 2 〜 3分 <stage 2>
<task>
</task>
<followup>
</followup>
</stage 2>
3 試験官と受験者によるロールプレイ
フォローアップ 1 〜 4分 <stage 3>
<task>
</task>
<followup>
</followup>
</stage 3>
4 4コマまたは6コマの絵を見ながらストーリーを作る
フォローアップ 2 〜 3分 <stage 4>
<task>
</task>
<followup>
</followup>
</stage 4>
5 緊張を解くような簡単な質問に答える 1 〜 2分 <stage 5>
</stage 5>
なお、本コーパスには音声データはありませんが、フィラー(つなぎ言葉)(<F> </F>)、言い直し(<SC> </SC>)や繰り返し(<R> </R>)なども非言語情報としてタグ付与されています。
さらに、全データには、性別、年齢、TOEIC や TOEFL スコア、インタビュー内で課されたタスクの種類などが学習者情報としてヘッダに付与されています。そのうち今回の調査で最も重要なのは、学習者の習得段階を示すレベル(<SST_level> </SST_level>)です。SST は学習者のレベルを初級から上級まで9つの習得段階に包括的に評価します。これらの習得段階別の情報があれば、学習者が異なる習熟度において、どのような言語使用をするのかを横断的に比較検証することができます。以下の表は、各レベルの習熟度と受験者数、および試験官と受験者の発話総語数を表しています。
SST レベル 習熟度 受験者数 試験官の
発話総語数受験者の
発話総語数1 Novice Low 3 1,754 413 2 Novice Mid 35 17,980 7,654 3 Novice High 222 103,979 95,494 4 Intermediate Low 482 227,103 308,477 5 Intermediate Low Plus 236 110,603 204,617 6 Intermediate Mid 130 62,563 132,885 7 Intermediate Mid Plus 77 39,872 87,574 8 Intermediate High 56 30,527 70,404 9 Advanced 40 24,204 56,118
| 4 | 学習者コーパスに見られる語用論的能力: 談話標識 |
今回の記事では、対話をよりスムーズにさせる機能を持つ I mean や well などの「談話標識(Discourse Markers)」に着目します。従来のコーパス分析で行われてきた表層的な語彙分析の手法で、語用論的能力の一端を示す談話標識の使用分布を調査してみましょう。
| 4.1 | 談話標識とは |
話し言葉における談話標識は、話し手の発話を聞き手により理解しやすくさせる語用論的機能を持ち、談話の首尾一貫性を保つのに役立つ言語項目です。以下に、Fung & Carter(2007)による談話標識の例とその機能について紹介します。[2] 下記のリストを見ても、いくつかの単語が複数の機能を持っていることがわかります。(下線の付いた項目は今回の記事で取り上げるものです。)
| ● Interpersonal(対人関係的な機能): | I see, I think, just, kind of, like, you know, well 等 |
| ● Referential(指示的な機能): | and, anyway, because, but, however, or, so, likewise 等 |
| ● Structural(構造的な機能): | and, finally, first, how about, next, now, well, yeah 等 |
| ● Cognitive(認知的な機能): | and, like, I mean, I see, I think, well, you know, sort of 等 |
| 4.2 | The NICT JLE Corpus における談話標識の使用 |
それでは、上記のリストに登場する談話標識のいくつかについて、本コーパスにおける使用分布を見ていきましょう。特に、学習者の習得段階によって談話標識の使用頻度がどのように異なるのか、また、試験官と繰り広げる対話の種類によってその談話標識の使用頻度は異なるかの2点から検証していきたいと思います。
3.2節でコーパスの各ファイルにアノテーションが施されていると書きましたが、付与されたタグを手掛かりに、習得段階と対話の種類を分別して頻度を計測することができます。習得段階については、各ファイルに付与された SST レベルを使います。対話の種類については、「モノローグ」、「ダイアローグ(カジュアル)」、「ダイアローグ(ロールプレイ)」の3つに分けることにしました。
| ● モノローグ: | 受験者が与えられた絵について描写する ― ステージ2、ステージ4 |
| ● ダイアローグ(カジュアル): | 試験官が主導して受験者とタスクに関連のある内容でくだけた会話をする ― ステージ1、ステージ2 〜 4のフォローアップ、ステージ5 |
| ● ダイアローグ(ロールプレイ): | 試験官と受験者がある特定の社会的な場面を想定したロールプレイをする ― ステージ3 |
以下に “well”, “I mean”, “kind of” そして “like” の4つの談話標識の使用分布を100,000語あたりの調整頻度で示した結果を紹介しましょう。[3] なお、SST レベル1と2の学習者は、談話標識の使用頻度が非常に低いことから含めていません。また、本コーパスには20名の母語話者が SST を受験したデータも含まれています。学習者の傾向と比較するために、母語話者の使用頻度についても計測しました。
| 4.2.1 | 談話標識(1): well |
▲ 発話例:
(レベル9: ダイアローグ(カジュアル)、ステージ1)
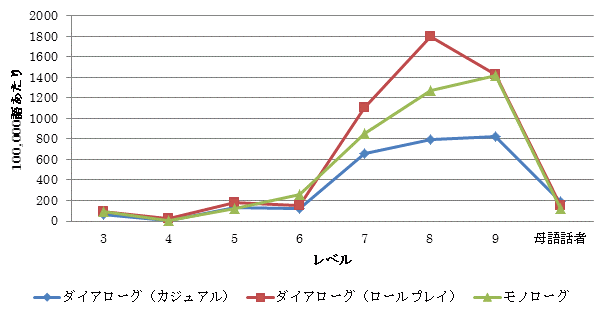
well は副詞(例: very well)、形容詞(例: He is well.)や名詞(井戸の well)と区別する必要がありますが、本コーパスには品詞情報が付与されていませんので、そのまま well を Analyzer で検索すると、これらの全てが抽出されてしまいます。本コーパスには、フィラーの機能を持つ well には全て <F> </F> のフィラータグが付いています。このフィラータグの付いた well が談話標識の機能を持つものとして判断し、こちらのみ抽出しています。
well の使用分布を見ると、レベル3からレベル6まではどの対話の種類においても使用頻度が低いですが、レベル7から使用頻度が上がり、特にレベル8のロールプレイにおいて最も頻度が高くなっています。この結果は母語話者のデータと比べると対照的です。母語話者の頻度は、レベル3からレベル6とほとんど変わりません。レベル7から9の学習者がダイアローグ(ロールプレイ)で well を使用する頻度が高いのは、ロールプレイのタスクにて試験官と対話を繰り広げる際、なんらかの意図を持って使用していた可能性も考えられます。
ところが、実際にどのような意図を持って受験者が発話していたのかは、個々の発話の文脈を確認する必要があります。4.1 で紹介したリストでは、well には3つの機能があるとされています。定義の後に、具体的な状況を( )内に示してみました。
| ● 対人関係的な機能: | 態度を示す(Yes とも No とも答えられない時) |
| ● 構造的な機能: | 話題の始まりと終わりを示す(話題を変える時) |
| ● 認知的な機能: | 思考過程を示す(発話の前に考える時間が必要な時) |
本調査では、well をフィラーに限定して抽出することは可能でしたが、表層的な抽出に留まっており、上記のように文脈に依存した言語機能の特定にまで至っていません。単に、受験者が言いよどんで well を使っているのか、No と断言するのを避ける意図で使っているのかまではこの段階ではわからないままです。
| 4.2.2 | 談話標識(2): I mean |
▲ 発話例: So, <F>ehm</F> could you tell me the hours, <F>ehm</F> <F>eh</F> I mean <R>flight</R> flight hours from Japan to <F>ahm</F> Pakistan?
(レベル5: ダイアローグ(ロールプレイ))
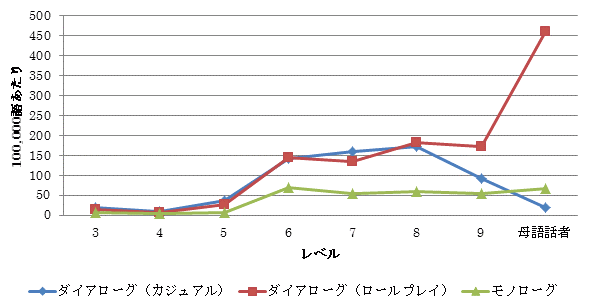
I mean に関しては、レベル6からレベル8ではダイアローグ(カジュアル)およびダイアローグ(ロールプレイ)で高い頻度の使用が見られ、モノローグでは頻度が低い傾向にあります。I mean は自分の発話の再構築や自己訂正の機能があるとされています。[4] 上記の発話例では、the hours を flight hours に訂正しています。レベル6以上の学習者は、自己訂正の機能で使っていると考えられるでしょう。一方、レベル9および母語話者が、ダイアローグ(カジュアル)で使用する頻度が低いことも特筆すべき分布でしょう。レベル8までの中上級学習者と異なり、自分の発話が不適切または不十分だと判断して訂正する機会が少ないのかもしれません。
さらに、母語話者の発話例も見てみましょう。以下の母語話者の例は、買い物のロールプレイから抽出した対話例で、I mean は発話を訂正する機能は持っていません。客である受験者が、店員である試験官と返品交渉をしており、受験者が自分の発言を和らげる機能を I mean に持たせていると言えるでしょう。さらにこの発話では well と組み合わせて使っています。
試験官: So we have a policy against exchanges as you know.
受験者: Well I mean, it still has all the tags on it except for the security tag that they took off.
学習者にとっては、特にレベル6からレベル8の中級レベルにおいて、I mean はモノローグよりもダイアローグでよく使われる談話標識と言えそうです。
| 4.2.3 | 談話標識(3): kind of |
▲ 発話例: So I think <SC>it's very</SC> <F>er</F> <SC>it'll</SC> <F>er</F> it's gonna a kind of hard to live in countryside now.
(レベル6: ダイアローグ(カジュアル)、ステージ 2のフォローアップ)
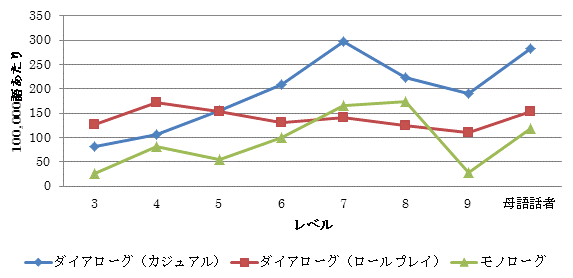
こちらの分布を見ると、ダイアローグ(カジュアル)ではレベル3からレベル7にかけて、またモノローグでは、レベル3からレベル8にかけて上昇傾向にあります。ところが、ダイアローグ(ロールプレイ)ではレベル4からレベル9にかけてほぼ横ばいかやや下降傾向にあります。モノローグは、レベル7とレベル8はダイアローグ(ロールプレイ)を上回りますが、他のレベルでは使用頻度が低い対話の状況と言えるでしょう。この結果を見ると、kind of は中級以上ではよりくだけた会話で使われる傾向にあると言えます。
kind of は態度を示す対人関係的な機能を持つとされています。[5] 上記の発話例を見ると hard という表現を和らげる効果を持っています。しかし、注意すべきなのは、この調査では「〜 の種類」を意味する名詞句(例: a kind of musical instruments)と談話標識を区別していません。この2つを区別して分類すれば、より適切に談話標識の使用分布を確認できるはずです。kind of の後ろに名詞を持つパターンを排除するなど、ある程度機械的に分類することはできますが、最終的には談話標識の機能を持つのか単純に名詞句なのかを目で見て一つ一つ分類しなければより正確な調査結果は得られないでしょう。
| 4.2.4 | 談話標識(4): like |
▲ 発話例: Like I can get there in like ten minutes or so.
(母語話者: ダイアローグ(カジュアル)、ステージ2のフォローアップ)

kind of と同様に、like に関しても、動詞(例: I like to play tennis.)や前置詞(例: You look like your father.)と区別する必要がありますが、Analyzer は自動的に区別した結果を表示してくれません。また、談話標識としての like の定義は先行研究によってもまちまちです。また、文法的には副詞や接続詞として分類されることもあるでしょう。前述の Fung & Carter(2007)は、態度を示す対人関係的な機能と話を膨らませる認知的な機能があるとしています。しかし、本調査では、より細かく like の機能を定義している Müller(2005)に沿って分析を進めることにしました。
Müller(2005)によると、談話標識の機能は「optionality(任意)」という概念に基づいて分類できるとしています。例えば、上記の母語話者の発話例から、like を全て取り除いても問題はありません。つまり、発話者が optional(任意)に追加して like を使用している場合を談話標識として判断するのです。さらに、以下のような4つの機能があると定義されています。
● 適切な表現を探す
● 数や量の概算を示す
● 例を示す
● 語彙的に強調する
談話標識の like を目で一つ一つ確認して手作業で抽出するのは非常に時間がかかります。こうした理由から、本調査では、レベル3、レベル6、レベル9そして母語話者の4つの発話者グループに限定して like の全例から談話標識の機能を持つものを特定した結果を示しています。like の用例を一つ一つ読み、optional かどうか、そして上記のような機能を持つかを確認したうえで、談話標識の like を特定し、頻度を計測した結果が上のグラフです。
習得段階が上がるにつれて、使用頻度は高くなりますが、特にダイアローグ(カジュアル)における使用頻度が高いことがわかります。その傾向は特に母語話者において顕著です。一方、ダイアローグ(ロールプレイ)やモノローグでの使用は、レベル3とレベル6に比べてレベル9と母語話者の方が多いものの、ダイアローグ(カジュアル)ほど使用はされていません。like も kind of と同じく習得段階が上がるほどよりくだけた会話で使われる談話標識と言えるでしょう。
なお、Müller(2005)は like の4つの機能を定義していますが、文脈を確認しながら抽出した like を機能ごとに分類することは非常に難しいことがわかりました。例えば上記の発話例の “like ten minutes or so” の like に着目しても、4つの機能が全てあてはまる可能性があります。談話標識は、研究者によっても定義が異なるだけではなく、多機能であり、さらに曖昧なケースが多く、より客観的に分類するのは非常に難しい現状があります。
| 3 | まとめ |
今回は、語用論分析の一環として、談話標識を The NICT JLE Corpus から習得段階別と対話の種類別に抽出してその使用分布を調査してみました。異なる談話標識の使用分布を見ると、談話標識によって使われる対話の種類が異なり、習得段階においてもその傾向が異なるようです。必ずしも習得段階が上がれば、その頻度が上昇するわけではありません。また、母語話者の傾向が最も習得段階の高い上級者のレベル9と同様であるとも限りません。こうした結果は、より学習者にスムーズな対話を実現してもらうために談話標識のどの項目をどの習得段階で教えると効果が高いのか、また学習者の習得段階が上がったとしても談話標識を過剰使用することで対話の運びに支障になっていないのかなど、日本人の英語学習者を教える教員に、興味深い示唆を与えてくれるものと思われます。
しかしその一方で、本調査を通して、言語項目を表層的にコーパスから抽出しても、その言語項目が本当に談話標識の機能を持っているのか、さらにどんな機能を持つ談話標識なのか判断するのは難しく、最終的には手作業による分類に頼らざるを得ないことがわかりました。さらに、その分類も多機能にわたるため、細かな分類が難しいだけでなく、主観的な判断に頼らざるを得ないという状況にも直面します。
今回の記事で、学習者コーパスを使って談話標識を観察するうえでの利点と難点の一端をご紹介できたことを願います。「文脈に依存しない表層(form)的な検証」における難点を踏まえて、次回は、「文脈に依存する言語機能(function)的な検証」を扱います。言語項目を手掛かりにコーパス分析をするのではなく、文脈情報に基づいて言語機能を特定し、見出した言語項目にアノテーションする分析方法です。特に相手に「依頼をする」際の言語表現に焦点を置き、語用論的分析に必要な準備や操作の可能性についてご紹介したいと思います。
〈参考文献〉
和泉絵美・内元清貴・井佐原均(編著)(2004)『日本人1200人の英語スピーキングコーパス』アルク。
Adolphs, S. (2008) Corpus and context: Investigating pragmatic functions in spoken discourse. Amsterdam: John Benjamins.
Fung, L., and R. Carter (2007) “Discourse markers and spoken English: Native and learner use in pedagogic settings.” Applied Linguistics 28: 410-39.
Müller, S. (2004) “‘Well you know that type of person’: Functions of well in the speech of American and German students.” Journal of Pragmatics 36, 1157-82.
Müller, S. (2005) Discourse markers in native and non-native English discourse. Amsterdam: John Benjamins.
Romero-Trillo, J. (2002) “The pragmatic fossilization of discourse markers in non-native speakers of English.” Journal of Pragmatics 34: 769-84.
Romero-Trillo, J. (2008) “Introduction: Pragmatics and corpus linguistics - a mutualistic entente.” In J. Romero-Trillo (Ed.), Pragmatics and corpus linguistics: A mutualistic entente. Berlin: Mouton de Gruyter, 1-10.
Rühlemann, C. (2010) “What can a corpus tell us about pragmatics?” In A. O'Keeffe, and M. McCarthy (Eds.), The Routledge handbook of corpus linguistics. Abingdon: Routledge, 288-301.
Thornbury, S. (2010) “What can a corpus tell us about discourse?” In A. O'Keeffe, and M. McCarthy (Eds.), The Routledge handbook of corpus linguistics. Abingdon: Routledge, 270-87.
|
〈著者紹介〉 三浦 愛香 (みうら あいか) 東京経済大学経営学部特任講師。専門は、コーパス言語学、第二言語習得。特に日本人英語学習者の語用論的能力の習得に関心がある。現在は、話し言葉の学習者コーパスに見られる発話行為を中心に研究を進めている。執筆に参加した辞書に、『エースクラウン英和辞典 第1版』(三省堂)、『グランドセンチュリー和英辞典 第3版』(三省堂)『プログレッシブ英和中辞典 第5版』(小学館)等がある。 |
〈注〉
[1] 主に Adolphs(2008), Romero-Trillo(2008), Rühlemann(2010)や Thornbury(2010)が例として挙げられます。
[2] 外国語の学習者が談話標識をどのように使用しているかを、母語話者と比較してコーパス分析を行った研究としては、Fung & Carter(2007)の他に、Müller(2004, 2005), Romero-Trillo(2002)等があります。
[3]
以下の表にあるように、対話の種類や習得段階別に含まれる総語数は異なります。そのため、頻度の相互比較が可能になるよう、粗頻度(実際にコーパスから観測された頻度情報)を100,000語あたりに頻度調整しました。
| SST レベル | ダイアローグ (カジュアル) |
ダイアローグ (ロールプレイ) |
モノローグ | 総数 |
|---|---|---|---|---|
| 3 | 56,551 | 22,914 | 16,030 | 95,495 |
| 4 | 185,149 | 72,040 | 51,292 | 308,481 |
| 5 | 123,100 | 33,108 | 48,409 | 204,617 |
| 6 | 82,310 | 21,510 | 29,065 | 132,885 |
| 7 | 55,386 | 13,438 | 18,751 | 87,575 |
| 8 | 44,943 | 10,508 | 14,953 | 70,404 |
| 9 | 36,886 | 8,116 | 11,116 | 56,118 |
| 母語話者 | 77,593 | 3,898 | 6,770 | 88,261 |
[4] Fung & Carter(2007)の定義を参考にしています。
[5] Fung & Carter(2007)の定義を参考にしています。
|
キーワードで書籍検索 コーパス corpus 談話標識 話し言葉 語用論 第二言語習得 |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |