

実践で学ぶ コーパス活用術 |
|
23 堀田 隆一 コーパスで探る英語の英米差
―― 実践編 ――
| © (WT-shared) Matthew 6476 |
前回の基礎編では、英語の英米差はある表現の頻度の差となって現われることが多いこと、したがってその比較にはアメリカ英語とイギリス英語のコーパスを併用することが適切であることを示しました。今回の実践編では、静かに流行の兆しのある gorgeous という形容詞を題材に、COCA と BNCweb を用いて、英語の英米差に迫ります。
| 1 | gorgeous の静かな流行 |
「ゴージャス」は日本語にもカタカナ語として借用されており、装飾や色などについて「華麗な、豪華な」という意味で定着していますが、英語ではこの語義よりも人や行為などに関する一般的な賛辞としての「すてきな、すばらしい」の語義で用いられるほうが普通です。例えば、フィギュアスケートの実況などで女性コメンテーターが Gorgeous! と感嘆するのを聞いたりします。この語義については『ジーニアス英和大辞典』によると《主に女性語・略式》とあり、OALD8 では (informal) とレーベルが貼られています。語感としては、日本語で主として若い女性が好ましいものに対して口語的に用いる「かわいい」に似ているとも言えます。
OED によると、gorgeous という語は15世紀終わりから用いられており、長い間「華麗な、豪華な」が基本的な語義でしたが、口語で一般的に賞賛を表わす新しい語義が19世紀後半から現れ出しました。しかし、新しい語義が広く用いられるようになったのは20世紀に入ってからのようであり、とりわけ頻度が高くなったのは20世紀後半から21世紀にかけてのここ数十年ほどのことではないかと疑われます。前回 Google Books Ngram Viewer で英米両変種での gorgeous の頻度の推移を調べましたが、グラフによると20世紀の間に漸減していた gorgeous の頻度が1980年代半ば以降に再び回復してきたように見えました。これはこの語が「すてきな、すばらしい」の新語義において特に口語で頻度が高まってきたことの反映かもしれません。しかし、アメリカ英語とイギリス英語とでは頻度もその伸び方も異なるようでした。いずれにせよ、新語義の定着と各変種での分布がどのような関係にあるのか、詳しく調べる必要があります。
| 2 | COCA によるアメリカ英語の調査 |
まず、COCA でアメリカ英語における状況を調べてみましょう。[1] COCA は現代アメリカ英語のコーパスですが、1990-2012年の間で5年刻みに通時的推移を確かめることもできますので、ある表現の頻度推移を見るのにも有用です。表示オプションで CHART を選択し、WORD(S) に gorgeous.[j*] (形容詞としての gorgeous)と入れて検索すると、以下のような結果が得られます。
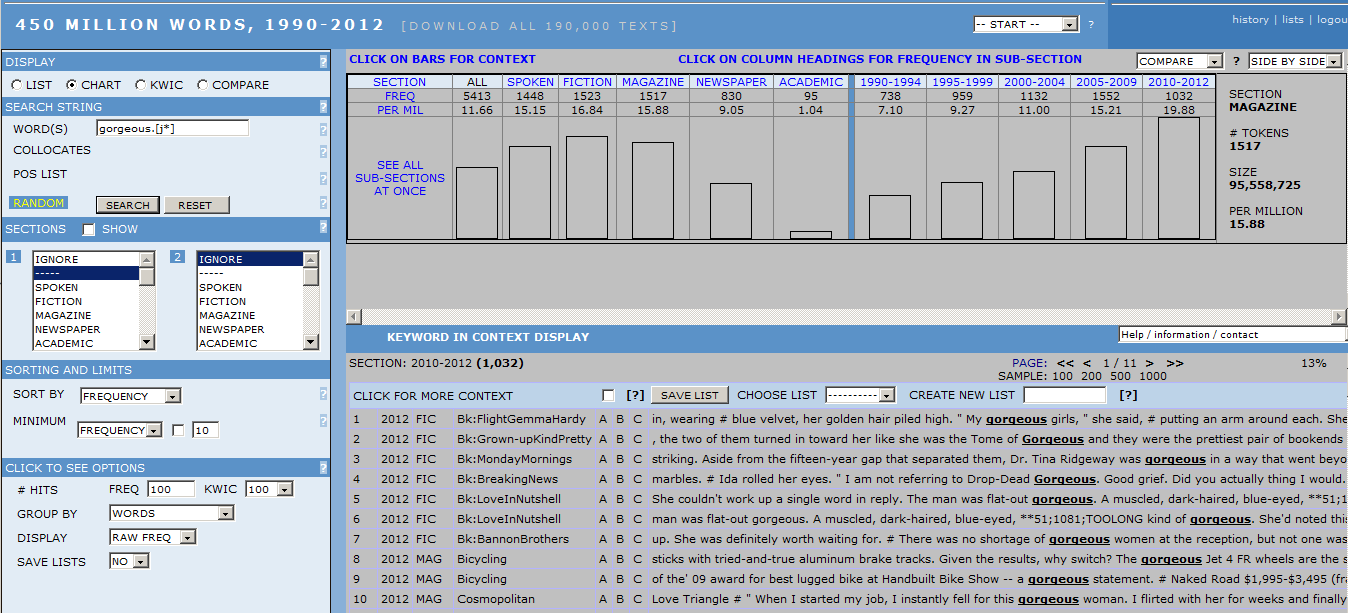
辞書で《略式》や (informal) というレーベルが貼られていたことから、とりわけ話し言葉において頻度が高いだろうと予想されました。確かに予想通り SPOKEN サブコーパスで頻度が100万語当たり15.15回と高かったのですが、意外と書き言葉のジャンルである FICTION, MAGAZINE, NEWSPAPER でもそれぞれ 16.84, 15.88, 9.05 回と、ある程度の頻度を示しています。それでも、例文を眺めると SPOKEN 以外のサブコーパスでも引用符に囲まれた発話のなかで gorgeous が用いられている場合が多いことから、話し言葉としての性質が強いことは確認できます。この解釈は、ACADEMIC サブコーパスで頻度が相対的に低いこととも矛盾しません。gorgeous dress, gorgeous flowers, gorgeous scenery など従来の「華麗な、豪華な」の語義も健在ですが、gorgeous woman, gorgeous body など人の性的な魅力を示す、口語的な形容詞としての使用例が目につきます。[2]
また、通時的にはこの20年間で着実に頻度を上げてきたことがわかります。観察する通時的な幅を拡げたいのであれば、姉妹コーパスである COHA を利用して、1810-2000年のほぼ2世紀にわたる頻度推移を確かめることができます。[3] 上記の COCA の場合と同じ要領で当該語を検索すると、以下の画面が得られます。
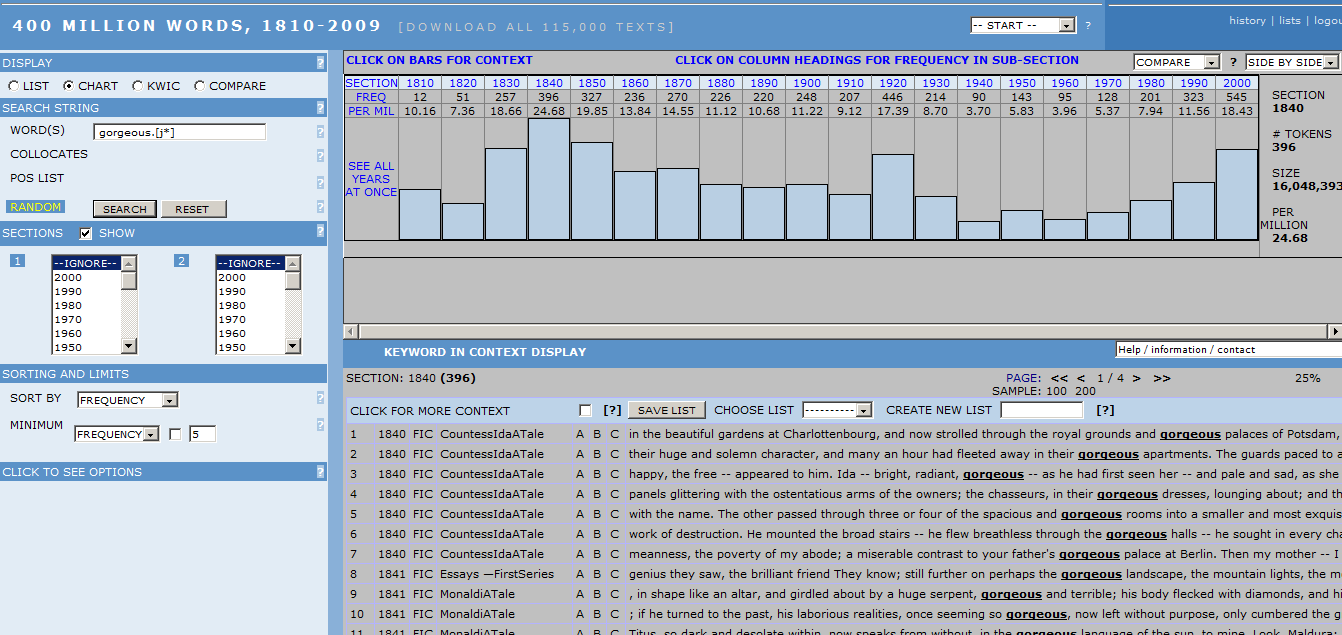
この語は、全体として20世紀中は低迷していましたが、1980年代に入ってから回復してきたようです。これは Google Books Ngram Viewer での観察と合致しています。19世紀半ばにピークを迎えたときの例文を眺めると、gorgeous palaces, gorgeous dresses, gorgeous rooms など本来の装飾的な華麗さを表す語義ばかりであり、新語義とみなすことのできる例はいまだ見受けられません。新語義と認められる例がちらほらと目につくようになるのは、20世紀後半を待たなければなりません。20世紀後半以降、本来の語義での用例が特別に増えたわけではないようですので、gorgeous 全体の頻度が漸増していったのは、新語義での使用の拡大に帰せられるといってよいでしょう。
| 3 | BNCweb によるイギリス英語の調査 |
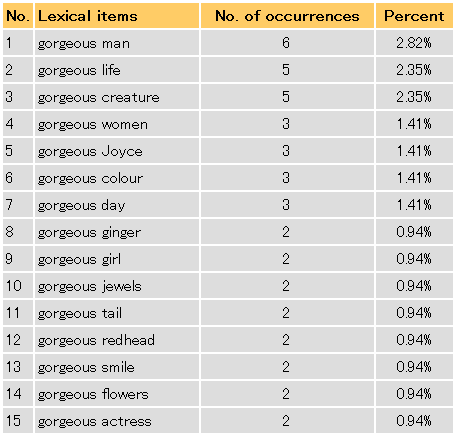
次に BNCweb で gorgeous の使用について調べてみましょう。[4] まずは、共起表現からです。検索語入力画面より gorgeous_AJ* _N* (gorgeous の次に被修飾名詞が来る組み合わせ)で検索した結果の画面より、右上のドロップダウンメニューから Frequency breakdown を選びます。gorgeous の右に共起しやすい名詞を降順に並べた一覧が、下図の通りに現われます。man, woman, girl, redhead など、人の賛辞に用いられる新語義とおぼしき用例が少なくないことが分かります。
次に、詳細な分布を調べましょう。検索画面に戻り gorgeous_AJ* 単体で検索し直してみます。先ほどと同じドロップダウンメニューから Distribution を選んでをクリックします。切り替わった画面では、様々なカテゴリーごとの gorgeous の頻度が一覧できます。最上部には話し言葉サブコーパス(約1000万語)と書き言葉サブコーパス(約9000万語)における gorgeous の頻度の違いが、以下の通りに整理されています。
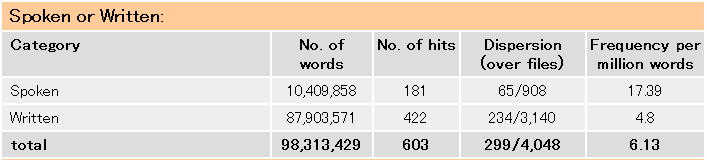
この表から明らかなことは、辞書の《略式》や (informal) というレーベルから予想される通り、この語は書き言葉よりも話し言葉で頻度が顕著に高いことです。100万語中の出現頻度は書き言葉で4.8回に対して話し言葉で17.39回あり、統計的には p < 0.0001 の水準で有意差が認められます。
しかし、話し言葉と書き言葉の差異以上に興味深いのは、話し言葉の場合の話し手の性別による分布です。現画面の上部にある Categories のドロップダウンメニューから Speaker: Sex を選択してをクリックすると、次の画面が得られます。
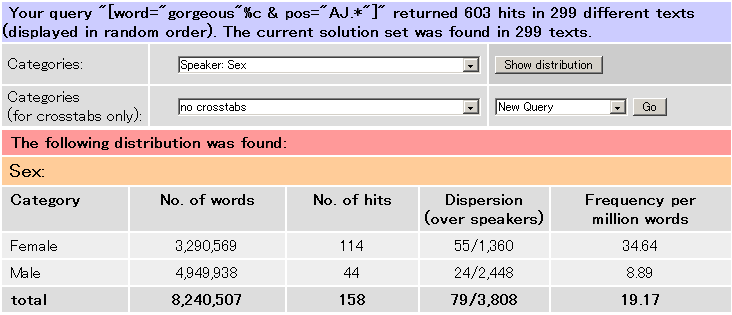
話し言葉サブコーパスにおいて gorgeous は男性には100万語当たり8.89回しか用いられていませんが、女性には34.64回も使われています(統計的には p < 0.0001 の水準で有意差があります)。次に、同じ画面の上から二つ目の Categories (for crosstabs only) のドロップダウンメニューから Speaker: Age を選んで、性別と年齢層を掛け合わせた頻度一覧を得ると、さらに興味深いことが分かります。以下に、画面を再現します。
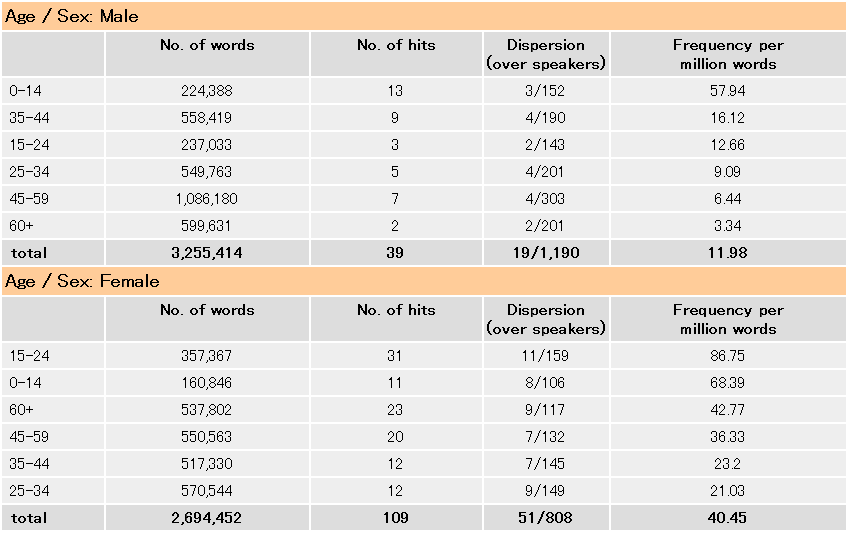
男性である程度の頻度をもって使用するのは14歳以下の年齢層に限られますが、女性には全体的によく用いられており、とりわけ24歳以下と45歳以上の年齢層が主たる使用者となっています。これらの分布から推測すると、BNCweb の代表する20世紀後半のイギリス英語の話し言葉に関する限り、gorgeous は若年層の女性にとりわけ好んで用いられる口語的な語と言えそうです。おそらくこの年齢層の女性から gorgeous の静かな流行が始まり、他の年齢層、とりわけより年配の女性にも拡がったものと思われます。一方、若年層の女性から同年齢層の男性にも拡散している様子がうかがわれます。非若年層の男性は gorgeous を最も用いない集団ですが、今後、この層でもある程度の頻度をもって使われる日が来るかもしれません。全体として、gorgeous の使用はここ1〜2世代の間に若年層の女性を中心に使用が拡大しているのではないかと推測できます。
| 4 | gorgeous の流行、米から英へ |
英米変種の比較という観点からは、いずれの変種でも gorgeous が1980年代以降、とりわけ話し言葉において頻度を上げ、今をときめく口語的形容詞となってきたようです。全体的な頻度としては、アメリカ英語でのほうがイギリス英語よりも上回っています。このことから、gorgeous は、アメリカ英語において先駆けて話し言葉で流行し、その後やや遅れてイギリス英語へもこの流行が主として話し言葉において伝わった可能性があります。イギリス英語では、とりわけ若年層の女性がこの流行に真っ先に反応し、この層を基点に口語的な語感をもった gorgeous の使用が女性一般に、そして同年齢層の男性へも飛び火しているのではないでしょうか。
この仮説を検証するには、コーパスから引き出された各使用例において gorgeous のどの語義が使われているのか、また共起語は何かなど、一つひとつ検討してゆく必要がありますし、さらに英米変種の通時的な比較を可能にする別のコーパスや文献に当たる必要もあります。しかし、少なくともコーパスからの証拠と矛盾しないシナリオの一つであるということは言えるでしょう。従来、英語の英米差の話題は、共時的で静的な観点から、ある表現の使用の有無を指摘するにとどまることが普通でした。しかし、今回のように英米変種間の横の共時的比較だけでなく、縦の通時的な視点を掛け合わせ、語の頻度の違いとその推移の問題、さらにはイギリス英語のアメリカ英語化の一環としてとらえると、英米差の話題もより立体的にアプローチできるのではないでしょうか。
| 5 | まとめ |
前回の基礎編と今回の実践編を通じて、英語の英米差とは何かを考え、その問題に迫るのにコーパスをどのように利用し得るかを示してきました。二変種の比較のためには規模や性質の異なる複数のコーパスを駆使する必要があり、使い方や結果の解釈には注意を要する点もあります。しかし、積極的に複数のコーパスを併用することにより、互いの欠点を補完することもできますし、問題を広い視点から動的な問題としてとらえることもできるようになります。とりわけ通時的な推移をも調査できるコーパス(群)を用いれば、その結果を注意深く読み解くことによって、英米差の問題に対して立体的なアプローチも可能となるのです。
最後に、英米変種だけが英語の変種ではありません。前回触れた ICE (International Corpus of English) のコーパス群をはじめ、世界中の英語変種が続々とコーパス化されています。このような環境において、今後は英語の変種間比較もますます盛んになっていくものと思われます。
|
〈著者紹介〉 堀田 隆一(ほった りゅういち) 慶應義塾大学文学部教授。2005年、英国グラスゴー大学にて Ph.D. を取得。専門は英語史、歴史言語学。英語史の記述と説明、とりわけ中英語の形態論の発達に関心がある。また、英語史の知見を活かし、いかに現代英語に関する素朴な疑問に答えられるか検討し続けており、2009年より毎日「hellog〜英語史ブログ」を執筆中。著書に『英語史で解きほぐす英語の誤解――納得して英語を学ぶために』(中央大学出版部、2011年)、The Development of the Nominal Plural Forms in Early Middle English(ひつじ書房、2009年)がある。その他、『ライトハウス英和辞典』(研究社)などの辞書の執筆に参加している。 |
〈注〉
|
関連書籍 |
|
キーワードで書籍検索 コーパス corpus 英語史 歴史 言語学 中英語 形態論 |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |