

実践で学ぶ コーパス活用術 |
|
36 鈴木 陽子
CHILDES を使って
―― 基礎編 ――
| © (WT-shared) Matthew 6476 |
| 1 | はじめに |
今月から2回にわたり、CHILDES という主に第一言語(母語)習得研究の分野で利用されているデータベースの使い方、その活用事例を紹介したいと思います。
第一言語習得と聞くと、英語学習や教育からは離れたトピックと思われるかもしれません。実際、第一言語を習得する環境は、辞書や教科書、教室を必要としないという点だけ考えてみても外国語を習得する環境とは大きく異なります。学習者にとって習得が難しいとされる項目を子どもは特別大変な苦労をせずに習得することができます。では、母語話者は語彙や文法をどのような言語使用や言語経験のなかで身につけていくのでしょうか。このような視点から子どものことばを観察してみると、学習と教育に向けた新しい視点を得ることができるかもしれません。
| 2 | CHILDES とは |
CHILDES(チャイルズ、Child Language Data Exchange System)は、自然発話データを共有するシステムを構築するという目的で、1984年に Brian MacWhinney と Catherine Snow によって始められた非営利の研究プロジェクトです。同時に、CHILDES は(i)発話データ、(ii)CHAT(チャット)と呼ばれるデータ表記の形式、(iii)CLAN(クラン)と呼ばれる分析プログラムからなるシステムの総称でもあります。発話データや分析ツールは以下の CHILDES のウェブサイトから誰でも無料でダウンロードし、利用することが可能です。[1]
|
CHILDES - Child Language Data Exchange System |
図1. CHILDES トップページ
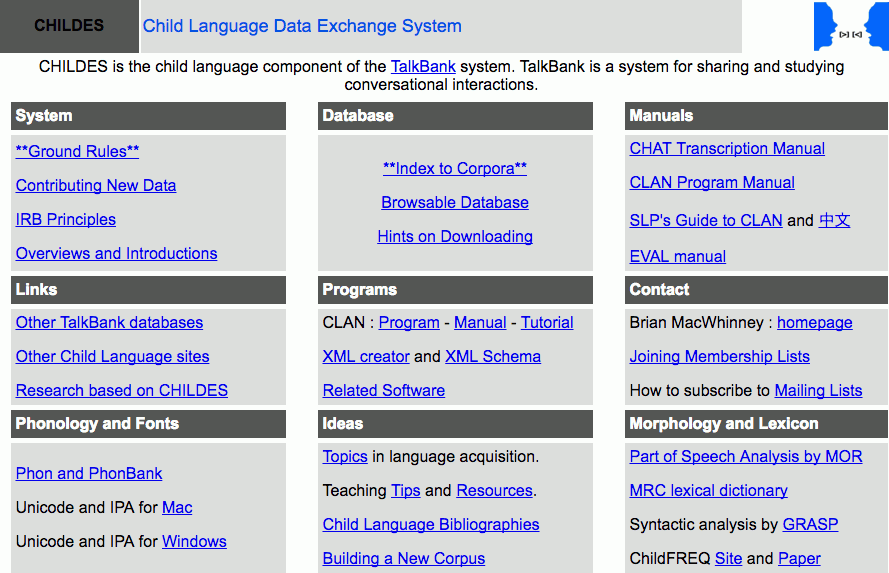
まずは、CHILDES を構成する発話データ、CHAT 形式、CLAN についてそれぞれ紹介します。
■発話データ
CHILDES には、現在、40以上の言語の自然発話データ(書きおこされたテクストデータ、トランスクリプトとも呼ばれます)が集められています。第一言語(母語)習得研究のためのデータが中心ですが、第二言語習得、バイリンガリズム、言語障害、手話研究など幅広い分野から集められたデータが提供されています。データによっては、発話データとともに音声や動画データも利用することが可能です。話し言葉、特に子どもと養育者との会話を分析する際には、書きおこされた発話を読むだけでは発話の状況や発話者の行動がわからない場合がありますが、音声や動画データはそのような場合に発話データを補完する資料として理解の助けになります。
データには子どもだけでなく、養育者や兄弟などの発話も含まれています。そのため、発話データを分析することで子どもに向けられたことば(child-directed speech)の特徴についても知ることができます。
Zip 形式で圧縮された発話データをダウンロードするには、上記のサイトから Database のセクションにある「**Index to Corpora**」をクリックし、ダウンロードしたいデータを選択します。例えば、北米の英語母語話者のデータをダウンロードしたい場合には、「ENG-NA」あるいは「ENG-NA-MOR(形態素タグつきデータ[2])」を、日本語のデータの場合には「EastAsian」を選択します。トップページで「Browsable Database」をクリックすれば、ブラウザから発話データを閲覧することも可能です。
■CHAT(Codes for the Human Analysis for Transcripts)
発話データが従うべき形式は CHAT 形式と呼ばれています。発話データを分析プログラム CLAN を使って分析するためには、データはCHAT 形式に則ったものである必要があります。例えば、CHAT 形式で書かれた発話データは以下のようになっています。このデータは、Adam という男児のデータの一部を抜粋したものです(Brown, 1973)。
図2. CHAT 形式のデータのようす
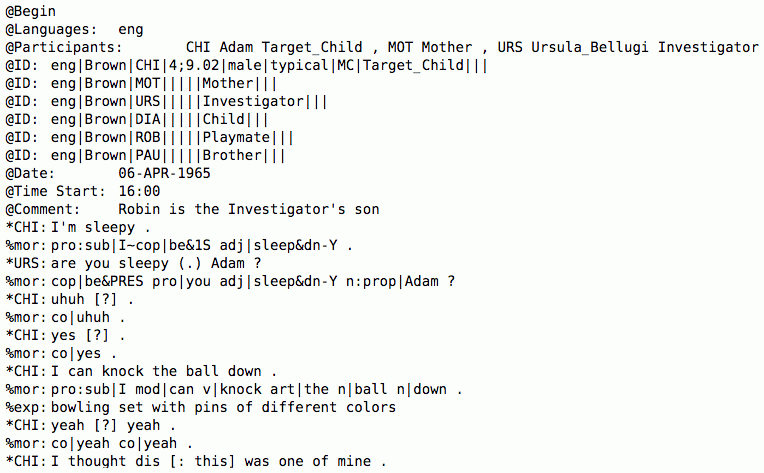
CHAT 形式で入力された情報は行の最初に書かれる3種類の記号(@、*、%)によって行(ティアと呼ばれます)が区別されています。
|
ヘッダ:
@で始まるティア。ファイルに関する情報(子どもの年齢やデータが収録された日時、対象言語、登場する発話者の情報など)が記載されています。CHAT 形式のファイルは、@Begin で始まり、@End で終わります。子どもの年齢は「年;月.日」の形式で表記されます。上のデータの場合、分析対象となっている子ども Adam は4歳9ヶ月2日であることがわかります。
メイン・ティア:
アスタリスク(*)で始まるティア。実際の発話が3文字の発話者コード(CHI や MOT)の後に記述されます。
ディペンデント・ティア:
%で始まるティア。その直前の発話に関する補足的な説明を与えます。例えば、%mor で始まる行には発話のなかに含まれる語の形態素や統語情報が、%exp で始まる行には状況についての付加的な説明が記述されています。
|
■CLAN(Computerized Language Analysis)
CLAN は、CHAT 形式で入力されたファイルを分析するためのプログラムです。CLAN を使うことによって、データ内の語の頻度を計算したり、特定の語を含む発話を抽出することができます。
最新の CLAN は以下のサイトから Windows 版と Mac 版を無料でダウンロードすることができます。
| 3 | CLAN を使った分析 |
実際に CLAN を使って CHAT 形式で書かれた発話データを分析してみましょう。
| 3.1 | 特定の単語を検索する: 子どもはどのように前置詞 of を使用しているか |
今回は、英語を母語として習得する Adam, Eve, Sarah という3人の子どもの発話データを対象に、前置詞 of の使用を観察してみたいと思います(Brown, 1973)。
英語学習者であれば、前置詞の of を知らないという人はいないでしょう。しかし、日本人学習者コーパスを使ったいくつかの調査から、日本人英語学習者が母語話者と比較して過小使用する語のひとつに前置詞 of があることが指摘されています(石川、2008; 金木、2013)。この理由は、母語話者がこれらの前置詞を定型的なコロケーションとして使用するのに対して、学習者は個々の語を単独で扱い、既成の(prefabricated)表現の使用に習熟していないためだと考えられています(石川、2008: 225)。
このような点を踏まえて、母語として英語を習得する子どもたちの of の発話がどのようなものか調べてみましょう。
手順1)CLAN を起動する: 「Commands」という小さなウィンドウ(コマンドウィンドウ)が開きます。
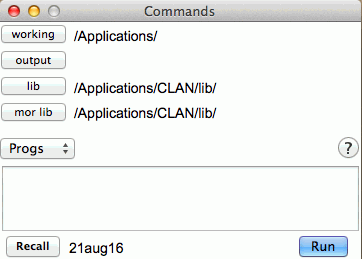
手順2)作業フォルダを指定する: ウィンドウ内の working ボタンをクリックします。分析したいファイルが入っているフォルダを選択し、Select Folder ボタンで指定します。指定すると、working ボタンの横にフォルダ名が表示されます。
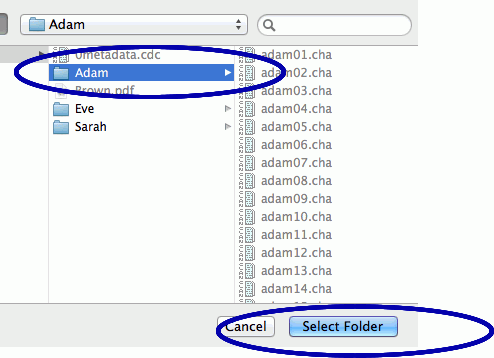
手順3)プログラム(コマンド)を選択する: Progs をクリックするとリストから動かしたいプログラムを選択することができます。ここでは、特定の語を含む発話のリストが見たいので、kwal(Key Word and Line)を選択します。
手順4)発話者や単語を指定する: プログラムに制限を加えたい場合には、オプションを指定します。例えば、データには養育者の発話も含まれていますが、今回は子ども(Adam)だけの発話を見たいので、テキストボックスに「+t*CHI」と入力して発話者を指定します。特定の単語や文字列を検索する場合には「+s "検索する語"」というオプションを使用します。まとめると、Adam の発話について、前置詞 of が含まれる発話を抽出する場合、テキストボックスには以下のように入力することになります(その他よく使われるコマンドやオプションについては次節でまとめます)。
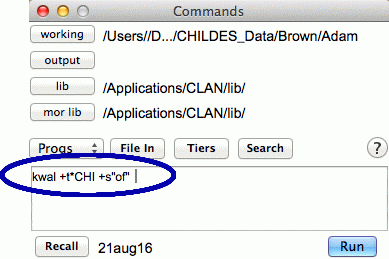
手順5)分析するファイルを指定する: File In ボタンをクリックして、分析対象とするファイルを選択します。今回は Adam のすべての発話データを分析対象とするので、Add all -> を選択します。ファイルが指定されると、テキストボックス内のコマンドの最後に@が表示されます。
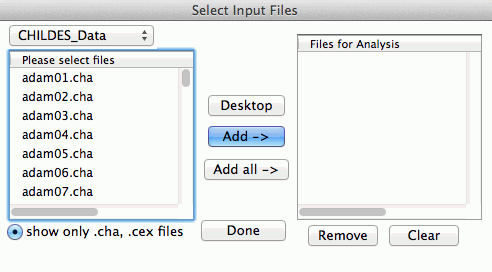
手順6)プログラムを動かす: Run ボタンをクリックします。同様の手順をEve と Sarah のデータについても行います。
| 3.2 | 分析結果を見る |
分析結果は CLAN Output という画面で次のように表示されます。

結果を整理し、それぞれの子どもについて前置詞 of を含む最初の10発話(不明瞭なものは除く)をまとめると次のようになります。
| Adam | |||
| *CHI: | piece of paper . | [2;5] | |
| *CHI: | pail of doughnuts . | [2;6] | |
| *CHI: | piece of paper for you . | [2;6] | |
| *CHI: | like a piece of meat . | [2;7] | |
| *CHI: | le(t) me (.) have (.) cup of coffee ? | [2;8] | |
| *CHI: | a cup of coffee . | [2;8] | |
| *CHI: | shame of me . | [2;9] | |
| *CHI: | two of them . | [2;10] | |
| *CHI: | walk (.) two of them . | [2;10] | |
| *CHI: | two of them . | [2;10] | |
| Eve | |||
| *CHI: | cheese sandwich (.) xxx that piece o(f) cheese . | [1;9] | |
| *CHI: | piece of cheese . | [1;9] | |
| *CHI: | a piece of celery . | [1;9] | |
| *CHI: | Fraser piece o(f) celery . | [1;9] | |
| *CHI: | just Mam piece o(f) celery . | [1;9] | |
| *CHI: | Eve piece o(f) celery . | [1;9] | |
| *CHI: | Eve have drink of milk . | [1;9] | |
| *CHI: | more piece of cheese . | [1;9] | |
| *CHI: | I want a piece of cheese . | [1;9] | |
| *CHI: | Jack fell down an(d) xxx pail of water . | [2;0] | |
| Sarah | |||
| *CHI: | piece of pa(per) ? | [2;3] | |
| *CHI: | dat [: that]you car of dere [: there] . | [2;9] | |
| *CHI: | you take piece of it . | [2;10] | |
| *CHI: | tell me what you think of me . | [2;11] | |
| *CHI: | I want drink of milk (.) Mummy . | [2;11] | |
| *CHI: | where's a pair of scissors ? | [3;0] | |
| *CHI: | you drink all of it . | [3;0] | |
| *CHI: | I want two of dem [: them]ri(ght) here . | [3;1] | |
| *CHI: | picture of my Bunny . | [3;2] | |
| *CHI: | <I go(t) to have some more though> [//]this full o(f) water . | [3;2] | |
これらの発話を見てみると、言語発達初期の子どもの of の発話には “piece of” や “cup of”, “pair of”, “two of” のように、数や量を表す定型的コロケーションが多く含まれていることがわかります。[3] どの子どものデータでも of を使った最初の発話は “piece of” です。その他、“think of” や “full of”, (上記のリストには含まれていませんが)“what kind of”, “take a picture of”, “tired of”, “heard of”, “on top of” などの使用も観察することができます。いずれの場合にも、子どもは of を自由結合句(偶然的な結合)としてさまざまな語と組み合わせるのではなく、複数の語から成る定型表現から使用をスタートさせているのが特徴的です。この傾向は3人の子ども全員に共通していますし、他の子どもを対象にした第一言語習得研究でも同じような特徴が観察されています(Tomasello, 1987, 2003; Rice, 2003)。
自然言語における談話は、個々の語というよりも高い頻度で使用されるコロケーションや単語連鎖から構成されます。母語話者に近い言語能力に至るには、学習者はこのような語を超えた単位の表現の使用に習熟している必要があり、言語学習や教育の観点からも重要です。
| 3.3 | その他よく使われるコマンドとオプション |
先ほどの例では kwal というコマンドを紹介しましたが、CLAN にはその他さまざまなコマンドとオプションがあり、それらを組み合わせることによって、より柔軟な分析を行うことができます。ここではすべてについて扱うことはできませんが、よく使われるコマンドとオプションを以下にまとめました。[4]
| コマンド名 | 機能 |
|---|---|
| combo | 単語の組み合わせを検索する(フレーズ検索)。 |
| freq | 対象ファイルに含まれる単語の一覧とその頻度を出力します。 |
| kwal | 特定の単語を含む発話のリストを作成する。 |
| mlu | 発話数・単語数および MLU 値(Mean Length of Utterance, 平均発話長[5])を計算する。 |
| コマンド名 | 機能 |
|---|---|
| +o | freq コマンドで得られる結果を出現頻度順(高頻度→低頻度)に表示する。指定しない場合にはアルファベット順に結果が表示される。 |
| +s/-s | combo, freq, kwal などのコマンドを使う際、検索する語を指定する。「-s」は除外する語を指定する。 |
| +t | 特定のティア(行)について分析する。 |
| +u | 複数のファイルの分析結果をひとつにまとめる。 |
| +w/-w | 発話を前後の文脈とともに抜き出す。例えば、「+w2 -w2」と指定することで特定の語を含む発話が前後2行とともに抽出される。 |
オプションの記述の際には、アスタリスク(*)をワイルドカードとして使うこともできます。例えば、次のようなコマンドを入力すると「pro で始まる語を含む発話(program, probably, propellers など)」を検索します。
kwal +s"pro*"
combo +t*CHI +s"I^think"
最初はコマンドの入力が複雑かもしれませんが、実際にコマンドやオプションを使ってプログラムを動かしてみることによって、思い通りにデータを検索・抽出することができるようになります。さまざまな語や表現について子どもがどのように使用しているかをぜひ確認してみてください。
| 4 | おわりに |
今回は CHILDES の使い方と分析方法について紹介しました。次回は、子どもの接続詞や複文の使用について CHILDES を使った分析事例を紹介していきたいと思います。
〈参照文献〉
Brown, R. (1973). A First Language: The Early Stages. Cambridge, MA: Harvard University Press.
石川慎一郎(2008)『英語コーパスと言語教育』東京: 大修館書店。
金木朝子(2013)「日本人英語学習者の語彙・フレーズの発達」『學苑』 870: 2-14.
MacWhinney, B. (2000). The CHILDES Project: Tools for Analyzing Talk. Third Edition. Mahwah, NJ: Lawrence Erlbaum.
宮田 Susanne(編)、Brian MacWhinney(監修)(2004)『今日から使える発話データベース CHILDES 入門』東京: ひつじ書房。
宮田 Susanne「CHILDES 日本語版」<http://www2.aasa.ac.jp/people/smiyata/CHILDESmanual/chapter01.html>(2016年8月30日アクセス)
Rice, S. (2003). “Growth of a lexical network: Nine English prepositions in acquisition”. In H. Cuyckens, R. Dirven, & J. Taylor (Eds.), Cognitive Approaches to Lexical Semantics. Berlin: Walter de Gruyter, 243-280.
Tomasello, M. (1987). “Learning to use prepositions: A case study”. Journal of Child Language 14: 79-98.
Tomasello, M. (2003). Constructing a Language: A Usage-Based theory of Language Acquisition. Cambridge, MA: Harvard University Press.
|
〈著者紹介〉 鈴木 陽子(すずき ようこ) 東京外国語大学世界言語社会教育センター特任講師。専門は第一言語習得、認知意味論、語用論。子どもの語彙(特に動詞)と文法の習得に関心がある。主な論文に、“The uses of get in Japanese learner and native speaker writing: A corpus-based analysis”(2015, Komaba Journal of English Education 6), “The acquisition of the Japanese imperfective aspect marker: Universal predisposition or input frequency”(2013, 共著、Japanese/Korean Linguistics 20), 『オノマトペ研究の射程――近づく音と意味』(2013, 分担執筆、ひつじ書房)等がある。 |
〈注〉
[1]
CHILDES(CHAT 形式や CLAN の使用を含む)を使用した研究を発表する際には、次の文献を引用することが必要です。また、発話データを使用した場合には、それぞれのデータに関連する文献を引用しなければなりません。
MacWhinney, Brian. (2000). The CHILDES Project: Tools for Analyzing Talk. Third Edition. Mahwah, NJ: Lawrence Erlbaum Associates.
[2] 形態素タグとは、発話のなかの語の品詞や語幹(あるいは見出し語)、時制などの付加的な情報を指します。CHILDES では形態素タグは %mor で始まる行に表示され、このタグを使うことで目的に応じた柔軟な検索が可能になります。
[3] このような数や量についてのやり取りのなかでは、前置詞 of が登場するだけでなく、日本人学習者にとって習得が難しいとされる冠詞(a, an, the)や不定代名詞(one, other, another, some, any, all, each, every など)が頻出する点も注目すべきでしょう。
[4] CHILDES の使い方については、日本語では、宮田(2004)と「CHILDES 日本語版」(ウェブサイト)が最も丁寧かつ網羅的な解説をしています。興味を持たれた方はぜひ参考にしてみてください。英語では、CHILDES のトップページから最新の電子版マニュアルをダウンロードすることができます。
[5] MLU とは、発話数に対する形態素数の比率を指し、言語発達の水準を測る指標のひとつとして、第一言語習得研究を中心に用いられています(Brown, 1973; 宮田、2004)。
|
キーワードで書籍検索 コーパス corpus 発話 |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |