

実践で学ぶ コーパス活用術 |
|
9 鎌倉 義士 学習者コーパスとは何か? |
© (WT-shared) Matthew 6476 |
「コーパス」という言葉は英語の研究や教育の場でよく耳にするようになりました。コンピューターとインターネットの発達によってコーパスの利用が容易となっています。言葉を集約したデータから言語使用の傾向を見出すにはコーパスの活用は欠かせません。対して、「学習者コーパス」はどうでしょうか? コーパスは知っていても、学習者コーパスについては知らないという読者の方々もいるでしょう。今回は学習者コーパスを取り上げ、その特徴について説明したいと思います。
| 1 | 学習者コーパスとは |
この連載でこれまで扱ってきたのは、ネイティブスピーカーの英語全般を対象にした一般コーパスと呼ばれるものです。それに対し、学習者コーパスは英語学習者から集めた言語データで構築されています。学習者の英語にはネイティブスピーカーの英語とはやや異なる特有の表現が見られます。学習者コーパスを分析することによって、英語学習者の表現にどのような傾向があるのかを知ることが可能となります。
コーパスの最大の利点は大量のデータによる分析が可能なことです。英語教員一人の経験則からイメージする学習者の特徴ではなく、大量の学習者データから見出される傾向を統計的に捉えることができます。学習者コーパスでは学習者がどのような間違いをするのかという分析が行われており、間違いの傾向と習熟度を比較することで、英語学習のある段階で頻出する間違いを予測することもできます。また、ネイティブスピーカーの使用傾向と比較することで、ある表現が過剰に使用されたり、反対にあまり使われていなかったりすることが明らかになります。言い換えれば、学習者はどういう表現が得意で、どういう表現が苦手なのかが分かるのです。
私が以前行った研究を例にあげますと、日本人英語学習者はネイティブスピーカーに比べて if を多用する傾向にあり、その句構造は特徴的なものでした。まず文頭にて If I can . . . や If we can . . . という副詞節で文を始めることが顕著でした。さらに、名詞節を導く if に注目してみると、日本人の英語には wonder if や think if というパターンが頻出するのに対し、ネイティブスピーカーは know if, see if, decide if など異なるパターンを多用していることが分かりました。こうした使用傾向の偏りは、文法的には誤りでなくても学習者の英語特有の不自然さを表わしていると言えるでしょう。
このように学習者コーパスは、ネイティブスピーカーと異なる学習者の英語表現の特徴を浮き彫りにし、学習者の英語を上達させるヒントを与えてくれるのです。学習者コーパスから得られる情報を活用すれば、より英語らしい表現を効率的に指導することができるようになるかもしれません。
| 2 | 学習者コーパスの特徴 |
| (1) | 一般コーパスとの違い |
学習者コーパスの特徴を理解するには一般コーパスとのデータ収集の違いを理解する必要があります。一般コーパスには、新聞・雑誌・書籍などから、また話し言葉を対象にするならばテレビやラジオの放送原稿や会話などから、大量の言語使用のデータが集められます。一般コーパスのデータの多くはコーパスとして収集されることを目的として発せられたものでなく、日常で使用される言葉がそのままコーパスを構築する要素となります。
対して、学習者コーパスのデータは自然な発話ではありません。あくまで学習者コーパスとして収集することを目的として、英語を学ぶ生徒や学生が書いた作文や、スピーチや対話を録音したものがデータとなります。学習者の言語習得過程を記述し分析することを目的とするには、厳密な規格となるコーパス・デザインが必要となります。さらに、日夜自然な発話で生産されていくデータと比べ、学習者コーパスのデータは研究者が学習者に依頼してはじめて生産されるデータです。そのため、データ収集には時間と手間がかかり、必然的に一般コーパスよりデータ量は少なくなります。
| (2) | データの対象 |
代表的な学習者コーパスには以下のようなものがあります。
| コーパス | 正式名称 | 対象 | データ量 | ||
|---|---|---|---|---|---|
| 日本人学習者のみ | JEFLL コーパス | Japanese EFL Learner Corpus | 日本人中高生1万人 | 69万語 | |
| NICE | Nagoya Interlanguage Corpus of English | 日本語を母語とする大学生・大学院生 | 12万語 | ||
| 日本人学習者+他言語を母語とする学習者 | ICLE | International Corpus of Learner English | 16の母語 | 日本・中国・ブルガリア・チェコ・オランダ・フィンランド・フランス・ドイツ・イタリア・ノルウェー・ポーランド・ロシア・スペイン・スウェーデン・トルコ・ツワナ | 375万語 (日:20万語) |
| ICNALE | International Corpus Network of Asian Learners of English | 10の母語 | 日本・香港・パキスタン・フィリピン・シンガポール・中国・インドネシア・韓国・タイ・台湾 | 128万語 (日:18万語) |
|
| ICCI | International Corpus of Crosslinguistic Interlanguage | 8の母語 | 日本・オーストリア・中国・香港・イスラエル・ポーランド・スペイン・台湾 | 84万語 (日:23万語) |
|
JEFLL コーパスは日本人中高生1万人を対象としています。中学や高校の英語教員にとって、ある生徒の英文に見る傾向がその生徒特有のものなのか、それともその世代の日本人英語学習者全体の傾向なのかを知りたい場合には JEFLL コーパスが有用でしょう。
NICE は日本語を母語とする大学生や大学院生の作文を基に構成されています。JEFLL コーパスが対象とする世代より上の大学生や大学院生は、より高度な英語表現を使用しているということが NICE で分かるでしょう。このように学習者コーパスを利用するにはデータの対象となる生徒や学生の性質を理解する必要があります。
ICLE は日本以外の学習者も対象としています。その中でも ICLE は学習者コーパスの標準となるほど対象・収集ルール・データ量が管理されたものです。ICLE が対象とする学習者は多岐にわたっており、2002年に発刊された第1版ではヨーロッパを中心とする11言語を母語とする学習者を対象にし、続く2009年の第2版(Version 2)では日本や中国などの学習者を加えて16言語の母語話者の英語を対象としています。第1版での11言語は第2版の16言語の中に含まれており、ICLE を利用するならば最新版の第2版を利用するのがよいでしょう。
ICNALE は、中国・韓国・台湾を含め日本に近いアジアの国々の学習者の英語を対象にしています。その背景には、言語的に近い性質を持つ母語の学習者は、第二言語を学ぶとき似た習得や間違いの傾向があるという仮説があります。英語を学ぶ際に、フランス人と日本人では異なる母語の影響が英語学習に現れることが予測されます。一方、日本人と韓国人では文化や文法の類似から似た傾向が見られるかもしれません。ICLE が主にヨーロッパ圏の英語学習者を対象にするのに対し、ICNALE が主にアジア圏の学習者を対象とするのは、それぞれのコーパス構築のプロジェクトを進めた中心となる大学がベルギーと日本にあり、その母語話者との対比を考慮したからではないでしょうか。
| (3) | データ収集のルール |
学習者コーパスを構築する際には厳格なルールを規定する必要があります。その理由は異なるデータを比較可能とするためです。ICLE のような複数の母語話者からデータを集めたコーパスでは異なる母語の英語学習者を比較することが可能です。同じ規格を共有するデータで比較すれば、その結果に信頼がおけるからです。この根底には言語習得理論の研究手法が関係しているように思えます。言語習得理論研究では行動主義に基づく心理学のような実験が行われてきました。科学的な研究をするにあたって、分析結果に影響する要因をコントロールする必要があります。学習者の言語習得を観察し分析するためには、厳密な実験計画のもとデータ収集を行わなければなりません。学習者コーパスを構築するためのデータ収集も同様なのです。
| 目標言語 | タスク | 学習者 | |||
|---|---|---|---|---|---|
| モード | [書き言葉/話し言葉] | データ採取 | [横断的/縦断的] | 内的・認知的 | [年齢/認知スタイル] |
| ジャンル | [物語/エッセイ/など] | 誘出 | [自発的/準備あり] | 内的・情意的 | [動機付け/態度] |
| 文体 | [叙事体/論説体] | 参考図書 | [辞書/原文/など] | 母語背景 | [日本語/中国語/など] |
| トピック | [一般/娯楽/など] | 時間制限 | [あり/なし/宿題] | L2 学習環境 | [ESL/EFL][学校レベル] |
| L2 習熟度 | [標準テスト得点] | ||||
上記表2は学習者コーパスを構築する際に注意すべき基準です。言い換えれば、上記基準を規定した上で学習者英語のデータは収集されているということです。目標言語・タスク・学習者の3点の基準を順に説明していきます。
目標言語とは、収集される学習者の英語の種類とも言えます。モードに関しては、書き言葉か話し言葉かで英語の特徴は変わります。学習者コーパスは、対象にするのが書き言葉(written)か話し言葉(spoken)かで独立した異なるコーパスとなります。ICLE が英語学習者の書き言葉を対象とするのに対し、話し言葉を集めたコーパスとして LINDSEI(Louvain International Database of Spoken English Interlanguage)があります。トピックに関しては、英語学習者に課す題によって作文内に表出する単語や表現は変わります。私が行った学習者コーパスの研究では、英語の勉強を話題とした作文を分析対象としたことから in the world という表現が頻出しました。
タスクとはデータを収集する環境設定を意味します。データ採取における横断的/縦断的とは、学習者からのデータ収集を1回のみ行ったのか、それとも学習者の変化を記録する目的で時間をかけて複数回収集を行うのかという違いを示します。現存する学習者コーパスの多くは、横断的なデータ採取によるものになります。辞書などの参考図書の有無は、作文を書くときに学習者が使用できる単語やフレーズの数や種類に影響します。時間制限も同様に、あれば限られた語や句や表現となるところが、時間無制限もしくは家に持ち帰り宿題としてよいならばより良い作文ができます。これらタスクの基準は第二言語習得理論の実験基準と類似しています。
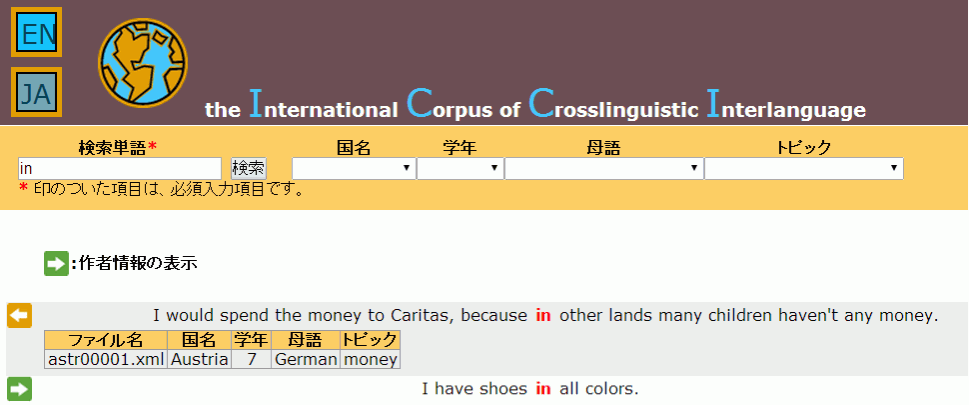
学習者の基準は、学習者の背景やプロフィールの違いを示します。その中でも母語背景は重要な要素で、異なる母語の学習者からの作文は異なるデータセットに集められます(このようなデータセットをサブコーパスといいます)。例えば、日本人英語学習者の作文からひとつのサブコーパスが作られ、中国人英語学習者の作文からは別のサブコーパスが作られます。この二つの異なるデータセットを比較すれば、日本人学習者特有の英語使用の傾向と中国人学習者の傾向を調べることが可能となります。他の学習者基準である L2(第二言語)学習環境・L2 習熟度や年齢などの情報は、学習者コーパスに添付されたデータに記録されることが多いようです。例えば、ICLE の CD-ROM は学習者コーパスに加えて学習者のプロフィールを収録したデータを収録しています。ICCI では検索単語を含む文を提示するコンコーダンスラインに作者情報の表示ボタンが設定されています。このボタンをクリックすると検索した文章を書いた学習者の国名・学年・母語などが表示されます。その情報から学習者の英語学習環境や習熟度、そして母語の影響などを推察することができます。
| (4) | データ量 |
コーパスは多くの語を含み、サイズが大きければ大きいほどが良いというのが大前提とされる理念です。なぜならば、コーパスの利点は収集された言語に何らかの傾向を見出すことができるという点です。少ないサンプル数では、分析の基となるデータに偏りがないか疑問を持たれます。例えば、学習者10人が持つ傾向と学習者1,000人が持つ傾向では自ずと分析結果の説得力が違います。すなわち、データ量が多ければ多いほど、分析結果に信頼をおけることになり、データ内の偏りも修正されます。
しかし、学習者コーパスは研究者が学習者に依頼してはじめてデータが提供されます。一般コーパスのように1億語を越えるデータ量を持つ学習者コーパスを構築するのは容易ではありません。私自身が大学院の学生時代にオリジナルの日本人スペイン語学習者コーパスを構築しましたが、10万語を収集するだけでもかなりの苦労を経験しました。この文章内で紹介する学習者コーパスの多くは100万語近くもしくはそれ以上の収録データ量を誇る学習者コーパスです。その信頼性に間違いはありませんが、一般コーパスに比べれば検索結果が少なくなります。ましてや、性別など学習者の特徴を限定すればするほど、分析する語句を含む検索結果が少なくなります。
コーパス言語学の理論では、必ずしも小さなコーパスが不利とはならないという考えがあります。[3] データ量が限られたコーパスをどのように活用するのかを考え、分析を進める必要があります。
今回は、一般コーパスとの違いを理解した上で、学習者コーパスの特徴となるデータの対象・データ収集のルール・データ量について説明してきました。次回は、代表的な学習者コーパスをもう少し詳しく紹介するとともに、学習者コーパスでの研究例をあげ、どのような学習者の英語の傾向を見出すことが可能なのかを説明していきます。
|
〈著者紹介〉 鎌倉 義士(かまくら よしひと) 愛知大学国際コミュニケーション学部英語学科准教授。2010年にイギリス・バーミンガム大学にて応用言語学博士号を修得(PhD in Applied Linguistics)。専門はコーパス言語学、認知言語学、言語習得理論。主に、英語の前置詞とその多義性、他言語習得などに興味や関心を持つ。単著に Collocation and Preposition Sense―A Phraseological Approach to the Cognition of Polysemy (Lambert Academic Publishing)、共著に『英語教師のためのコーパス活用ガイド』(大修館書店)、『英国王のスピーチ(名作映画完全セリフ音声集――スクリーンプレイ・シリーズ)』(フォーインスクリーンプレイ事業部)、Multidisciplinary Perspectives on Second Language Acquisition and Foreign Language Learning (Oficyna Wydawnicza Wacław Walasek) などがある。 |
〈注〉
|
関連書籍 |
|
キーワードで書籍検索 コーパス corpus |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |