

実践で学ぶ コーパス活用術 |
|
26 阿部 真理子 コーパスを使って英語学習者の言語使用の実態を探る
―― 前編 ――
| © (WT-shared) Matthew 6476 |
| 1 | 学習者コーパスの可能性 |
これまで日本全国の学校で、どれくらいの量の英作文、英文エッセイ、英文レポートが宿題として出されてきたのでしょうか。トピックやテーマに差はありますが、もしこれらの宿題がすべて電子化され、データベースとして整備されていたとしたならば、どうでしょう。英語を学習する日本人がどのように英語という言語を使用しているかの実態を客観的に探ることができるのではないでしょうか。日本人が苦手とする語彙や文法項目について、より詳細に知ることができるのではないでしょうか。そしてそのような分析が積み上げられた先には、より効果的な学習支援の方法が見えてくるかもしれません。
このような発想のもと、書き言葉だけではなく、話し言葉も含めて、さまざまな学習者コーパスが構築されてきました。コンピュータの発達にともなって、学習者コーパスが出現するようになるまでは、小規模なデータにもとづいた散発的な分析しかできませんでした。しかしいまや、個々の学習者の習熟度がわかる学習者コーパスまでが公開されていて、自由に使えるようになりました。[1] さらには、これらの学習者コーパスに、学習者がどのように誤った使い方をしているのか、というエラー情報を付与することができれば、あとは計量的に分析することが可能になります。ですので、以下のような疑問に関する答えを探ることもできます。
(A) 英語学習の過程で、自然に消滅していくエラーと、学習が進んでも消滅しないエラーとは何か?
(B) 学習段階によって、つまづく傾向にはどのような違いがあるのか?
そこで、これから2回にわたって、コーパスを使った英語学習者の言語使用の分析事例について紹介します。
| 2 | 学習者コーパスを用いたエラー分析が抱える問題点 |
英語学習の過程で、学習者が誤って用いている言語の分析には、コーパスの威力が大いに発揮されます。そしてその研究成果は、教育に応用されることが期待できます。しかし、エラー分析を行うにあたって、大きな問題点がいくつかあります。一つ目は、機械によるエラーの自動判定が、いまだ研究途上にあるので、エラーに関する情報を手作業によって付与しなければならないということです。このエラー付与の作業には、多大な時間と労力がかかります。二つ目は、エラーの判定には恣意的な部分もあり、判定者の解釈が入ってしまうことです。そして三つ目は、学習者のエラーをどのような形態で分類するのかということについてはさまざまな議論があるため、学習者コーパスごとに異なるタイプのエラーが付与されているという点です。
| 3 | エラー情報つき学習者コーパスを分析してみる |
以上のような問題点はありますが、エラーは学習者の言語使用の実態を知るためには、重要な一つの側面であるといえます。たとえば二つ目の問題を解決するためには、以下のような3点のルールを設けることで、エラー判定に統一性を持たせることができます。[2]
それでは、どのようにしてエラー分析を行うのか、具体的に見ていきましょう。ある中高一貫校に通う中学1年生から高校3年生までの英作文(3万語分)における時制のエラーを分析する例をご紹介します。ここで用いた学習者データは、JEFLL コーパスとして公開されているものの一部に、著者がエラータグを付与したものです。
(1) まずは、時制が正しく用いられている場合の頻度を算出します。そのためには、品詞タグが付与された学習者データを用意しなければなりません。品詞タグにはさまざまな種類があるので、使用するデータの特徴に合ったものを選ぶことが大切ですが、ここでは CLAWS C7 tagset を用いています。なお、CLAWS の品詞タグは、日本の中学・高校で指導される文法体系とすべてが一致しているわけではないので、注意が必要です(たとえば、学習者が文頭で接続詞として用いている “so” を副詞と認識します)。
(2) 次に、時制が誤って用いられている場合の頻度を算出します。そのために、手動でエラー情報を付与します。ここでは、NICT JLE コーパス[3] に用いられているエラータグの一部を使っています。[4]
<s>We held a school festival <prp_lxc1 crr="on"></prp_lxc1> September 14 and 15.</s> <s>Our class <v_tns crr="made">make</v_tns> a piramid's inside.</s> <s>It <v_tns crr="was">is</v_tns> very dark, and almost a ghost house.</s> <s>At first, I didn't enjoy it very well, but <prp_lxc1 crr="on">at</prp_lxc1> the second day, I <v_asp crr="got">was getting</v_asp> interested in it.</s> <s>Especially, girl's reaction <v_tns crr="was">is</v_tns> better than boy's.</s> <s>After the festival, we <v_tns crr="held">hold</v_tns> <jp>うちあげ</jp> until the middle <prp_lxc1 crr="of"></prp_lxc1> night.</s> <s>We also <v_tns crr="enjoyed">enjoy</v_tns> <pn_lxc crr="it">there</pn_lxc>.</s>
※ <jp> </jp> は日本語で書かれた語を示しています。
この中から、時制のエラーの例を見てみましょう。
Our class <v_tns crr="made">make</v_tns> a piramid's inside.
<v_tns> </v_tns>(動詞に関する時制のエラー)というタグで囲まれた部分の中に修正候補として、crr="made" が入っています。これは、本来であれば動詞の過去形(made)を使用するべきところ、誤って現在形(make)が使用されてしまったことを示しています。
(3) 最後にコーパス分析用ソフトの検索機能を使って、エラーの総数(例:v_tns を検索)を出したのち、エラー率を計算します。ここでは、AntConc を使用しています。
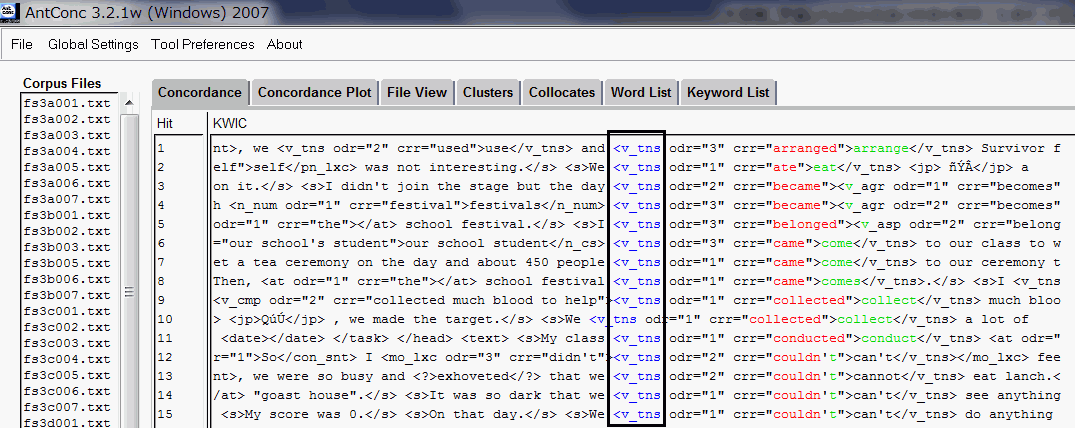
※図中の odr=" " のタグは修正すべき順序を表しています。
このように(1)〜(3)の手順を踏んで把握することができたエラーの総数と、エラーを含む例文をくわしく見ていくと、さまざまな結果が見えてきます。[5] たとえば、中学2年生から高校3年生までの5年間に、時制のエラー率はほとんど変化しません(10%前後で推移)。この10%前後というエラー率はあまり高くないといえますが、時制のエラーは学習が進んでも消滅しないエラーといえるかもしれません。そして、興味深いのは時制のエラーのうち、そのほとんど(98%)が「必要なときに過去形が使用できていない」エラーであるということです。
この分析に使用した作文のトピックは、「学園祭について」でした。過去に行われた学園祭について記述するわけですから、過去形の使用が多くなるはずですが、文中に異なる時制が混在してしまう傾向(ここでは、過去形と現在形)がありました。つまり、適切な時制(過去形)を一貫して使うことができないことが明らかになったのです。ですから、冒頭で挙げた「(A)英語学習の過程で、自然に消滅していくエラーと、学習が進んでも消滅しないエラーとは何か?」という問いに対して、時制のエラーは学習が進んでも消滅しないエラーである可能性が高いと答えることができます。
さらに分析を相のエラーにも広げてみると、「(B)学習段階によって、つまづく傾向にはどのような違いがあるのか?」という問いに対する答えが見えてきます。中学1年生と2年生は「進行形」を、高校生は「完了形」を誤って使用する傾向があったのです。ですから、このように学習者コーパスを使うと、日本人英語学習者にとって、正しく使用することが難しい項目であると考えられる時制と相のエラーについて、詳細に見ていくことができるのです。
今回は、特定のエラーについて注目しました。次回は、品詞ごとにエラーを分析することによって見えてくる全体像について紹介します。
〈参考文献〉
Ellis, R., and G. Barkhuizen (2005). Analysing learner language. Oxford: Oxford University Press.
和泉絵美・内元清貴・井佐原均(編)(2004). 『日本人1200人の英語スピーキングコーパス』東京: アルク。
阿部真理子(2013). 「時制と相のエラー分析」投野由紀夫・金子朝子・杉浦正利・和泉絵美(編)『英語学習者コーパス活用ハンドブック』東京: 大修館書店、132-39頁。
|
〈著者紹介〉 阿部 真理子(あべ まりこ) 中央大学理工学部教授。ランカスター大学にて、修士号(Language Teaching: TESOL)を取得。専門は、コーパス言語学、英語教育。共著に、『英語学習者コーパス活用ハンドブック』(大修館書店)、『コーパス英語類語使い分け200』(小学館)、『新 TOEIC テスト900点突破英単語ドリル』(アルク)などがある。最新の研究論文は、“Frequency change patterns across proficiency levels in Japanese EFL learner speech” Journal of Applied Language Studies, Special issue on “Learner language, learner corpora” 8(3), pp. 85-96. その他の論文については、以下を参照。https://chuo-u.academia.edu/MarikoAbe |
〈注〉
[2] Ellis and Barkhuizen(2005)をご参照ください。
[3] NICT JLE コーパスについては、和泉他(2004)および以下の Web サイトをご参照ください。https://alaginrc.nict.go.jp/nict_jle/
[4]
表1. エラータグの一覧表
| 品詞 | エラーカテゴリー | エラータグ | エラー例 |
|---|---|---|---|
| Adjective (形容詞) |
Inflection (活用) |
<aj_inf> | *more tall |
| Comparison (原級・比較級・最上級の用法) |
<aj_us> | Jane is taller than Mary, but Mary is the *best basket ball player. | |
| Quantifier (修飾語としての数量詞) |
<aj_qnt> | There was *few traffic on the road. | |
| Word choice (語彙選択) |
<aj_lxc> | It is a *genius diamond. | |
| Adverb (副詞) |
Inflection (活用) |
<av_inf> | *more far |
| Comparison (原級・比較級・最上級の用法) |
<av_us> | She came back *most quickly than me. | |
| Position (位置) |
<av_pst> | I have difficulty *often in understanding her. | |
| Word choice (語彙選択) |
<av_lxc> | He worked *hardly today. | |
| Article (冠詞) |
Article (冠詞) |
<at> | *a apple |
| Noun (名詞) |
Inflection (活用) |
<n_inf> | *childerens / *housewifes / *peoples |
| Number (単数・複数) |
<n_num> | many *book / one *books / each *books | |
| Countability (可算・不可算名詞の使い分け) |
<n_cnt> | *a music / *musics | |
| Case (格) |
<n_cs> | my *friend house | |
| Word choice (語彙選択) |
<n_lxc> | *type (a typewriter) | |
| Preposition (前置詞) |
Complement (補部) |
<prp_cmp> | I look forward *to see you again. |
| Word choice (語彙選択―従属前置詞以外の前置詞) |
<prp_lxc1> | It was held *on June. | |
| Word choice (語彙選択―名詞・動詞・形容詞などに続く従属前置詞) |
<prp_lxc2> | Tom's teacher accused him *about cheating. | |
| Pronoun (代名詞) |
Inflection (活用) |
<pn_inf> | *themselfes |
| Agreement (数・性別の一致) |
<pn_agr> | It is a good book. I like *them. | |
| Case (格) |
<pn_cs> | *We school festival is very good. | |
| Word choice (語彙選択) |
<pn_lxc> | I often ask *me why I work so hard. | |
| Verb (動詞) |
Inflection (活用) |
<v_inf> | *sleeped |
| Subject-verb agreement (主語・動詞の人称・数の一致) |
<v_agr> | there *are a cat / there *is cats / he *like / I *likes | |
| Tense (時制) |
<v_tns> | I *eat breakfast this morning. | |
| Aspect (相) |
<v_asp> | The people *weren't knowing the reality. | |
| Form (形) |
<v_fml> | to *drinks / is *drink | |
| Word choice (語彙選択) |
<v_lxc> | She *is black and short hair. | |
| Modal verb (助動詞) |
Word choice (語彙選択) |
<mo_lxc> | The phone's ringing. I *am going to answer it. |
| Conjunction (接続詞) |
Word choice (語彙選択) |
<con_lxc> | He hit a homerun, *and I didn't. |
※スペリングのまちがいは非常に数が多いので、分析対象外としています。しかし、begin の過去形を bagan と書くなど、辞書に記載のない動詞の活用形についてはこの限りではなく、動詞の活用のエラー(v_inf)とみなしています。
※本来は、1語あるいは2語であるべき単語の間違いも不問としています(例: *basket ball)。
[5] 時制のエラーに関する詳細な分析結果については、阿部(2013)をご参照ください。
|
関連書籍 |
|
キーワードで書籍検索 コーパス corpus |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |