

実践で学ぶ コーパス活用術 |
|
27 阿部 真理子 コーパスを使って英語学習者の言語使用の実態を探る
―― 後編 ――
| © (WT-shared) Matthew 6476 |
前回は、特定の言語項目(時制)のエラーについて、学習者コーパスを用いて分析する方法を紹介しました。今回は、エラー分析の結果を品詞とエラータイプごとにまとめることによって見えてくる学習者言語の実態について紹介します。
| 1 | 品詞ごとのエラー率はどのように変化するのか? |
使用する学習者データは、前回と同じです。中高一貫校に通う中学1年生から高校3年生までの英作文3万語です(JEFLL コーパスとして公開されているものの一部に著者がエラータグを付与しています)。分析の手順も前回と同じです。
(1) 各品詞の使用頻度を算出するために、CLAWS C7 tagset を用いて品詞タグを自動付与します。そしてコーパス分析用ソフト(AntConc)を使って、品詞ごとの総数を出します。
以下は、品詞タグを付与した学習者データの例です。たとえば、冠詞の総数を出したい場合は、“AT” のタグを検索します。
<s>Through_II the_AT school_NN1 festival_NN1 ,_, each_DD1 of_IO our_APPGE classmates_NN2 became_VVD friendly_JJ ._.</s>
(2) エラーの頻度を出すために、手作業でエラー情報を付与します。前回と同様、NICT JLE コーパス[1] に用いられているエラータグを使います。[2] 何が誤りで何が正しいかの判定は難しいので、明らかに誤っているものにだけ着目します。そして、なるべく最小限かつ簡単に正しい英文として訂正できるような修正候補をあげます。
以下は、エラータグを付与した学習者データの例です。この例文は、作文の一番初めに出てくる文でしたので、定冠詞の the ではなく、不定冠詞の a を使うべきでした。
<s>Our school had <at odr="1"crr="a">the</at> festival.</s>
(3) コーパス分析用ソフト(AntConc)を使って、エラーの総数(例: 冠詞のエラーであるならば <at> を検索)を出したのち、エラー率を計算します。
(4) 分析対象としたすべてのエラー項目の正用法と誤用法の比率を品詞ごとにまとめ、学年別に出します。
図1. 品詞ごとの正用法比率の変化(阿部、2007)
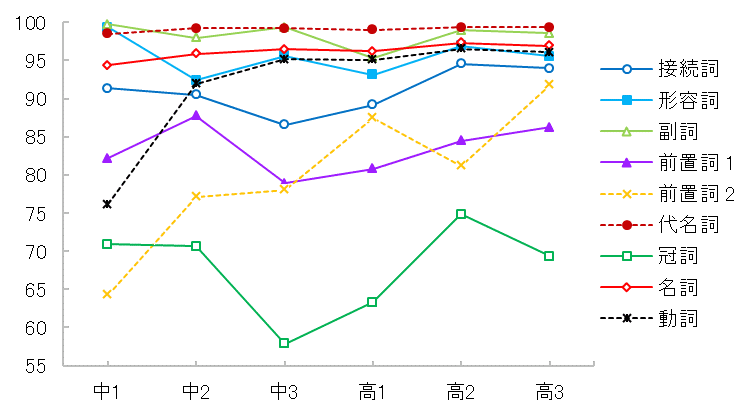
結果をまとめた図1. の正用率の変化を見ると、品詞によって以下の4つの傾向があることがわかります。
| 1. | 全般的に正用率が高い | ⇒ | 「代名詞、形容詞、副詞、名詞、動詞」 |
| 2. | 中学3年生から正用率が安定して上がる | ⇒ | 「接続詞、一般的な前置詞」 |
| 3. | 正用率に増減がある | ⇒ | 「名詞・動詞・形容詞などに続く従属前置詞」 |
| 4. | 全般的に正用率は低いが、正用率の上昇が大きい | ⇒ | 「冠詞」 |
この傾向を見ると、品詞によって正用率の変化に差があることが明らかです。しかし、品詞という枠組みだけで学年別の変化を見ていて、エラーの種類との関連は見ていません。そこで次に、エラータイプという分析観点を取り上げます。
| 2 | 品詞ごとのエラータイプの内訳に差はあるのか? |
ここでは、James(1998)を参考にして、エラーを3つのタイプに分類してみます。
(A) 誤形成(misformation): 誤った品詞や語形などが使われている。
例. I am very interesting in your story.
(B) 脱落(missing): 必要な語が脱落している。
例. There is (*) book on the desk.
(C) 余剰(unnecessary): 不必要な語が挿入されている。
例. We will visit (to) you again.
分析対象としたすべてのエラー項目を上記3つのタイプに分類して、品詞ごとにエラータイプの内訳を100%に換算したのが、以下の図です。
図2. 品詞別エラータイプの内訳(阿部、2007)
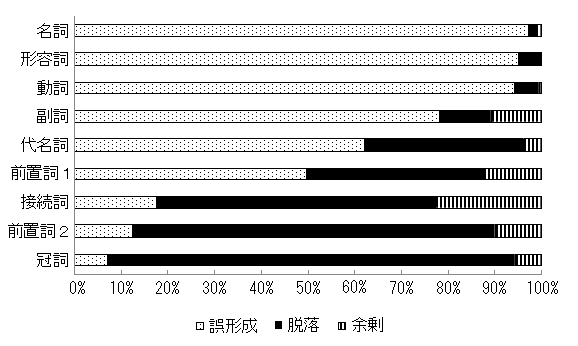
結果を見ると、以下のようなことがわかります。
1. 誤形成のエラー率が高い品詞と、脱落のエラー率が高い品詞がある。
2. 誤形成と脱落、誤形成と脱落と余剰のように、異なるタイプのエラーが見られる品詞がある。
3. どの品詞も、余剰のエラー率はそれほど高くない。
| 3 | エラーの学年別変化とエラータイプに関係性はあるのか? |
それでは次に、学年別の正用率の変化(図1)と、品詞別のエラータイプの内訳(図2)について、合わせて考察してみましょう。エラータイプごとに順番に見ていきます。
| (A) | 誤形成 |
このタイプのエラーが多いのは、「名詞」、「形容詞」、「動詞」、「副詞」、「代名詞」でした。これらの品詞は、中学1年生における動詞をのぞくと、全般的に正用率が高いのが特徴的です(90%以上の正用率)。
名詞
「単数と複数」に関するエラーが目立ちましたが、これは学習が進むにつれ、使用する名詞の種類や修飾語の使用が増えるためだと考えられます。名詞は平均して10%以下のエラー率ですが、学年が上がるにつれて、さらに減少していきます。
動詞
特に中学1年生は be 動詞の使用が多く、「be 動詞+動詞の原形」という組み合わせのエラーが目立ちます。また助動詞や to 不定詞に関しても、動詞の「形」に関するエラーが多く見られます。このような傾向は、中学3年生になると、「一般動詞+一般動詞」というように動詞を二重に使ってしまう傾向に変わっていきます。また動詞は、脱落のエラー率が高いわけではありませんが、「主語+動詞」がセットで丸ごと文章の中から脱落しているケースが初学年には見受けられました。
さらに、動詞の誤形成エラーの中で大きな問題となると思われる「主語・動詞の人称・数の一致」のエラー率は、中学高校の6年間を通してほとんど変化しませんでした。これは話し言葉のデータを対象としたエラー研究[3] の結果と異なります。話し言葉においては、「主語と動詞の人称・数の一致」のエラー率は習熟度が上がるにつれて減少する傾向がありました。
形容詞、副詞
語彙選択以外のエラーに関して、形容詞は「活用」や「数量詞」のエラーが目立ち、副詞は「位置」に関するエラーが多く見られます。
代名詞
中学1年生では格変化が正しく学習できていないため、「格」のエラーが目立ちます。学年が上がると長い文章が書けるようにはなってきますが、前の文章で出てきた事柄を正しい代名詞で受けることができないため、高校1年生では「数と性の一致」のエラーが多くなります。
また、何を指しているのかが明らかでない代名詞の it は日本人英語学習者の作文によく見受けられるものであり、読み手が悩まされますが、図2を見ると、脱落のエラーも多いことがわかります。これは主語や目的語として必要な代名詞が文章の中から脱落しているためといえるでしょう。しかしながら、代名詞と同じく文の主構成要素となる名詞と動詞は、代名詞ほど脱落するエラーの比率が高くありません。代名詞の正用率は他の品詞に比べると低くはありませんが、主語や目的語となる代名詞の指導には注意が必要であると思われます。
| (B) | 脱落 |
このタイプのエラーが多いのは、「名詞・動詞・形容詞などに続く従属前置詞」、および「冠詞」でした。どちらも中学・高校の6年間で、大きく正用率が上昇している品詞です。また接続詞もこのグループに入ります。
名詞・動詞・形容詞などに続く従属前置詞
エラーの中では、動詞に続く前置詞が脱落している例が多く見られましたが、正用率の伸びが最も大きく、中学1年生から高校3年生までの間に、64%から92%まで上昇しています。6年間のうちに、多少上がったり下がったりもしていますが、大きな傾向として上昇しているといえます。
冠詞
中高6年間の間に正用率が上がったり下がったりしていますが、最も低い中学3年生の時点での正用率58%が、高校2年生では75%まで上昇しています。[4] しかしながら、日本語にない文法項目である冠詞は、やはり学習が難しいと考えられます。
冠詞に関しては、話し言葉のデータを用いた研究[5] においても、脱落タイプのエラーが多いことが明らかになっています。
接続詞
正用率は中学3年生では87%ですが、高校3年生では94%になります。それほど大きな向上ではありませんが、正用率は上昇しています。中学3年生あたりから、文と文をつないで一文を長くしようとする傾向が出てきますが、等位接続詞(特に and)を利用することなく、コンマのみで文を並置するという傾向がありました。中学1・2年生のほうが中学3年生よりもエラーが少ないのは、単文が多く接続詞の使用が多くないからといえるでしょう。
文中で and が抜けている(脱落エラー)だけではなく、不必要に挿入されている(余剰エラー)両方の傾向があるので、 and の使い方については注意して指導する必要があるといえます。
| (A&B) | 誤形成と脱落 |
「一般的な前置詞」は、誤形成のエラーと脱落のエラーとの比率が比較的近いことが特徴的です。
一般的な前置詞
正用率は中学3年生の79%から高校3年生の86%まで伸びています。着実に正用率は上がっていますが、使用されている前置詞は学園祭の開催時期や場所を表すものに限定されている傾向がありました。これは、作文トピックが「学園祭について」であったため、その影響を受けていると考えられます。正用法率が90%を超えていないことを考えると、やはり学習しにくい品詞の一つであると考えられます。
| (C) | 余剰 |
このタイプのエラーに関しては、どの品詞もそれほど高くありませんが、「接続詞」のエラー率が比較的高いことがわかりました。
接続詞
脱落のエラー率も高かったですが、並置表現において、不必要な等位接続詞として、and を多用している例も多くありました。また高校1年生になると、書き手の意図していることをくみ取るのが難しい接続詞のエラーが増えてきます。中学3年間で英語の基本的な文章構造について理解した学習者が、高校生になってより長くて複雑な構造の英文を生み出そうと試行錯誤するからといえるでしょう。そのため、余剰エラーだけではなく、誤形成のエラーも増えてきます。
| 4 | まとめ |
以上、誤形成エラーは、全般的に正用率が高めの品詞に多いけれども、脱落エラーは、正用率が低めである品詞(冠詞、前置詞1、前置詞2、接続詞)に多いことが明らかになりました。後者の品詞は、中高生の学習者にとって文中における必要性を認識するのに時間がかかるのかもしれません。
しかしながら、「名詞・動詞・形容詞などに続く従属前置詞(前置詞2)」の脱落のエラーに見られるように、増減はありながらも学年を追うごとに正用率が上昇しており、そのうちエラーが消滅するのではないかと思われる項目もあります。ですので、どのエラーが学習者にとってより深刻であるかを把握した上での指導は大切です。また異なるタイプのエラーが見られる品詞もありました。誤形成と脱落(例: 代名詞と一般的な前置詞)、誤形成と脱落と余剰(例: 接続詞)などは、注意が必要といえるでしょう。
これまでの結果を品詞ごとにまとめてみましょう。
「代名詞」、「形容詞」、「副詞」、「名詞」、「動詞」
●正用率が高めである。
●語の選択や、語形を間違えて使う傾向がある。
「接続詞」
●中学3年生ころから、正用率が安定して上がる。
●等位接続詞、特に and を脱落させたり、不必要に使ってしまったりする傾向がある。
「一般的な前置詞」
●中学3年生ころから、正用率が安定して上がる。
●前置詞の選択を誤ったり、必要なときに使わなかったりする。
「冠詞」
●正用率が他の品詞と比較して低い。
●脱落させてしまうことが多い。
「名詞・動詞・形容詞などに続く従属前置詞」
●正用率に増減がある。
●特に動詞のあとで脱落させてしまうことが多い。
品詞によって学年を追うごとに正用・誤用の出現傾向に違いがあることがわかりました。また、品詞とエラーのタイプには関連性の強いものがあり、品詞の誤用率とも関係があることが明らかになりました。
ここで紹介したエラー分析は、手作業で3万語分のデータに9つの異なる品詞(前置詞1、2を二つと数えて)に関するエラー情報を付与していますので、規模としてはあまり大きくありません。より大規模なデータを用いて、誤形成、脱落、余剰のエラータイプと品詞の関係を分析した研究に関しては、Tono(2013)があります。
二回にわたって、コーパスを使って、学習者言語の実態についてエラーという観点から分析する例を紹介しました。しかし、何を誤ってしまうのかについてばかりではなく、何ができるのかという分析も必要です。さらには、使うことはできるのだけれども、必要以上に使いすぎている語・句・構文についても理解したいところです。また使用頻度が少なすぎる、あるいは全く用いられていない語・句・構文に関する情報を得ることも重要です。日本人英語学習者が用いている言語がどのような状態にあるのかを理解することで、英語教材やシラバスの開発、そして指導が効果的に行われるようになるのではないでしょうか。
〈参考文献〉
Abe, M. (2007). “A corpus-based investigation of errors across proficiency levels in L2 spoken production.” JACET Journal, 44 (pp. 1-14).
James, C. (1998). Errors in language learning and use: Exploring error analysis. Harlow: Longman.
Tono, Y. (2013). “Criterial feature extraction using parallel learner corpora and machine learning.” In A. Díaz-Negrillo, N. Baillier, and P. Thompson (Eds.), Automatic treatment and analysis of learner corpus data (pp. 169-203). Amsterdam: John Benjamins.
阿部真理子(2007).「JEFLL コーパスに見る品詞別エラーの全体像」投野由紀夫(編著)『日本人中高生一万人の英語コーパス “JEFLL Corpus”――中高生が書く英文の実態とその分析』東京: 小学館、146-58頁。
和泉絵美・内元清貴・井佐原均(編)(2004). 『日本人1200人の英語スピーキングコーパス』東京: アルク。
|
〈著者紹介〉 阿部 真理子(あべ まりこ) 中央大学理工学部教授。ランカスター大学にて、修士号(Language Teaching: TESOL)を取得。専門は、コーパス言語学、英語教育。共著に、『英語学習者コーパス活用ハンドブック』(大修館書店)、『コーパス英語類語使い分け200』(小学館)、『新 TOEIC テスト900点突破英単語ドリル』(アルク)などがある。最新の研究論文は、“Frequency change patterns across proficiency levels in Japanese EFL learner speech” Journal of Applied Language Studies, Special issue on “Learner language, learner corpora” 8(3), pp. 85-96. その他の論文については、以下を参照。https://chuo-u.academia.edu/MarikoAbe |
〈注〉
|
関連書籍 |
|
キーワードで書籍検索 コーパス corpus |
|
複写について|
プライバシーポリシー|
お問い合わせ
Copyright(C)Kenkyusha Co., Ltd. All Rights Reserved. |